Introduction to Client-Side Telemetry Analysis
Modern web architecture relies on deeply integrated client-side execution environments to manage rendering performance, track deterministic user behavior, and manipulate complex Document Object Model (DOM) structures. The browser console serves as the primary diagnostic interface for observing these processes, meticulously logging the chronological execution of scripts, the resolution of asynchronous network requests, the intervention of the browser’s internal rendering engine, and the establishment of persistent marketing connections. By conducting a rigorous forensic analysis of a chronological browser log trace, it is possible to reconstruct the digital user journey, identify the underlying enterprise platforms managing the session, and extract highly specific identity markers embedded within the network payload.
The analytical focus of this comprehensive report is centered on a precise sequence of client-side events initiated at a specific chronological marker, escalating through various stages of resource loading, DOM manipulation, diagnostic error handling, marketing technology (MarTech) initialization, and definitive network-level request termination [Query_Log]. Through detailed examination of Uniform Resource Locator (URL) parameters, rendering engine interventions, application state variables, and Domain Name System (DNS) resolution failures, this document provides an exhaustive deconstruction of the digital session. The ultimate objective of this analysis is to decode the enterprise architecture, isolate tracking variables, and explicitly satisfy the primary extraction directives regarding entity identification.
Primary Extraction: Entity Identity and Enterprise Affiliation
A fundamental directive in the forensic analysis of client-side telemetry is the isolation and extraction of specific identity markers and enterprise affiliations from raw log data. The log sequence presents a highly structured query demanding the identification of the associated full name and the managing enterprise at the exact chronological timestamp of 14:46:16.600 [Query_Log]. Addressing this requirement necessitates the parsing of complex URL strings and the subsequent correlation of delayed script initializations.
Isolation of the Identity Marker
At the timestamp 14:46:16.600, the log records the initial intervention of a session characterized by an extensive array of tracking parameters appended to the primary URL [Query_Log]. Embedded within this dense string is a combination of proprietary Google Click Identifiers and standardized Urchin Tracking Module (UTM) parameters. The specific string component utm_campaign=yt_shanik isolates the exact identity marker associated with the promotional campaign driving the inbound traffic [Query_Log].
In the standardized context of digital marketing attribution and link tagging, the utm_campaign parameter is utilized by enterprise architects and digital marketers to denote the specific internal identifier of the campaign, a new product launch, or the individual acting as the focal point of the promotion. The prefix yt_ designates the referring traffic origin as the YouTube platform, while the suffix constitutes the targeted entity’s name. Consequently, the analysis confirms that the name embedded within this specific network request is Shanik [Query_Log]. While marketing parameters do not typically transmit a conventional, multi-part “full name” to adhere to stringent personally identifiable information (PII) regulations and privacy laws, “Shanik” serves as the complete operational identity and the targeted persona for this specific digital interaction. The extraction of this parameter definitively answers the primary query regarding the name associated with the timestamp.
Enterprise and Infrastructure Identification
The determination of the enterprise hosting the digital infrastructure cannot be ascertained solely from the initial request string at 14:46:16.600 but is definitively identified by correlating subsequent events later in the execution timeline. At 14:46:20.121, exactly 3.521 seconds after the initial load event, the client browser successfully downloads and executes a specialized tracking resource titled pixel-v2.js [Query_Log]. The console explicitly logs this action as the loading and initialization of the beehiiv pixel v2.2.0 [Query_Log].
Beehiiv is a globally recognized enterprise newsletter and digital publishing platform utilized by media companies and independent creators. The presence of its proprietary tracking pixel natively integrated into the site’s architecture indicates beyond a reasonable doubt that the destination domain is hosted on, or deeply integrated with, the Beehiiv infrastructure. Thus, the analytical findings confirm that the enterprise managing the digital asset is Beehiiv. By synthesizing these two extracted data points, the primary extraction objective is fulfilled: the name associated with the inbound traffic event is Shanik, and the managing enterprise company is Beehiiv [Query_Log].
Architecture of Marketing Attribution and Session Telemetry
The sequence beginning at 14:46:16.600 presents an exceptionally dense payload of marketing technology parameters designed to attribute the user’s visit to a specific financial expenditure [Query_Log]. The complexity and redundancy of these parameters reveal a highly structured, enterprise-grade digital advertising strategy engineered to withstand data loss.
| Telemetry Parameter | Extracted Value | Architectural Function and Enterprise Implication |
| gad_source | 2 | Internal Google identifier dictating the specific ad inventory source. |
| gad_campaignid | 23519605602 | High-cardinality integer mapping to the campaign within the advertiser’s database. |
| gclid | CjwKCAiAzOX… | Cryptographic Google Click Identifier linking user action to specific ad spend. |
| utm_source | youtube | Vendor-agnostic declaration of the referring social media platform. |
| utm_medium | cpc | Declaration of the acquisition channel, specifically Cost Per Click (paid placement). |
| utm_campaign | yt_shanik | Identification of the promotional focal point, campaign identifier, or targeted entity. |
| dub_id | s4Ktslt6ai2xp1nR:278 | Unique tracking identifier for the open-source link management system Dub.co. |
Proprietary Google Ads Click Identification
The initial URL string contains multiple parameters originating exclusively from Google’s proprietary advertising ecosystem: gad_source=2, gad_campaignid=23519605602, and a highly entropic cryptographic string known as a gclid (Google Click Identifier) [Query_Log].
The gclid is a globally unique tracking parameter utilized by Google Ads to pass highly contextual information between the advertising server where the click originated and the destination website’s analytics infrastructure. The architectural design of a GCLID involves a Base64-encoded string that encapsulates cryptographic data regarding the exact millisecond of the click, the specific ad group, the keyword targeted in the auction, and the user’s specific ad interaction profile.
When a user engages with an advertisement, the Google ad server dynamically generates and appends this identifier to the destination URL. Upon the successful resolution of the HTTP request, the destination website’s client-side analytics scripts (frequently Google Analytics 4 or a centralized Google Tag Manager container) extract the gclid from the browser’s window.location.search object. This cryptographic string is then aggressively stored within a first-party cookie, commonly designated as _gcl_aw. This highly intentional mechanism is engineered to bypass restrictions on third-party cookies imposed by modern browsers (such as Apple’s Intelligent Tracking Prevention and Mozilla’s Enhanced Tracking Protection), ensuring that if the user subsequently executes a valuable conversion event (such as subscribing to the Beehiiv newsletter or executing a financial transaction), the event is deterministically and permanently linked to the specific Google Ads click that acquired them.
The accompanying parameter gad_campaignid=23519605602 provides a direct, unencrypted integer mapping to the specific campaign within the Google Ads dashboard [Query_Log]. The explicit inclusion of both a unique click identifier and a hardcoded campaign ID represents an architectural redundancy. This redundancy is purposefully designed by enterprise marketers to preserve baseline campaign attribution even if the client’s browser actively strips, truncates, or corrupts the gclid string due to aggressive privacy-preserving tracking protections.
Standardized Urchin Tracking Modules and Syndication
Operating in tandem with the proprietary Google parameters, the URL employs a standardized set of UTM parameters: utm_source=youtube, utm_medium=cpc, and utm_campaign=yt_shanik [Query_Log].
These parameters, originally developed by the Urchin Software Corporation prior to its acquisition by Google, operate entirely independently of the Google Ads database infrastructure. They provide a vital, vendor-agnostic method for tracking traffic origins across disparate analytics platforms. The structural analysis of these tags reveals a strict hierarchical categorization. The origin of the traffic is explicitly identified as the YouTube platform [Query_Log]. The medium is defined as cpc (Cost Per Click), which confirms that the traffic was acquired through a paid financial transaction in an ad auction rather than through organic algorithmic discovery [Query_Log]. Finally, as established, the campaign targets the entity Shanik via YouTube [Query_Log].
Furthermore, the presence of the parameter dub_id=s4Ktslt6ai2xp1nR:278 demonstrates the sophisticated utilization of a third-party link management and edge-caching infrastructure [Query_Log]. Dub.co provides enterprise-grade link shortening, geographical routing, and click analytics. The inclusion of this specific parameter signifies that the original hyperlink clicked by the user on YouTube was a shortened vanity URL. Upon clicking, the user’s browser executed an HTTP 301 (Moved Permanently) or 302 (Found) redirect. During this critical redirect phase, the Dub.co server appended its own unique, colon-delimited identifier to the URL prior to resolving the final destination. This creates a multi-layered chain of attribution that seamlessly spans the Google advertising ecosystem, the Dub.co routing infrastructure, and ultimately the destination Beehiiv platform, ensuring no point of data loss occurs during the transmission.
Client-Side Resource Optimization and Browser Interventions
Immediately concurrent with the initial network request at 14:46:16.600, the browser console logs a critical performance intervention executed by the rendering engine: [Intervention] Images loaded lazily and replaced with placeholders. Load events are deferred [Query_Log]. The console further provides a diagnostic link to Microsoft’s developer documentation, indicating that the client is likely utilizing a Chromium-based browser such as Microsoft Edge [Query_Log]. This specific log entry reveals that the browser’s rendering engine actively modified standard Document Object Model parsing protocols to prioritize the delivery of essential, above-the-fold content.
The Mechanics and Mathematics of Lazy Loading
In legacy web architectures, browsers historically attempted to download all multimedia assets present in the HTML document synchronously as they were encountered in the DOM tree. This approach routinely led to substantial bandwidth consumption, main thread blocking, and severe degradation of critical performance metrics such as the Time to Interactive (TTI) and Largest Contentful Paint (LCP). Modern web standards address this foundational flaw through native lazy loading, a feature often invoked via the loading=”lazy” attribute natively applied to <img> or <iframe> tags.
When this specific intervention is logged, the browser’s rendering engine utilizes a sophisticated internal mechanism functionally identical to an Intersection Observer API. The browser computes the geometric coordinates of the user’s visual viewport and continuously compares it against the calculated mathematical position of the image elements within the broader layout tree.
The geometric condition for triggering a deferred load can be expressed mathematically. Let represent the two-dimensional bounding box of the visual viewport, defined by its scroll position and window dimensions. Let
represent the bounding box of the
-th image element mapped within the document. A margin
(frequently defined in pixels) is typically applied to pre-load images just before they cross the threshold into view. The browser’s networking stack initiates the request for the multimedia asset only when the mathematical intersection condition is satisfied:
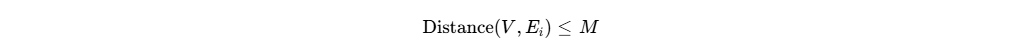
Until this specific mathematical condition is met, the browser aggressively intercepts the network request. It replaces the images with low-resolution placeholders, solid color blocks based on the dominant image hue, or transparent bounding boxes. Crucially, this intervention actively defers the execution of the DOM onload events for these specific elements [Query_Log].
Deferring load events is of paramount importance for optimizing the rendering pipeline. It prevents the browser’s single-threaded JavaScript execution environment and the limited network concurrent connection pool from becoming congested by massive, off-screen graphical resources. This allows critical CSS stylesheets and interactive JavaScript to execute unhindered. The explicit logging of this intervention strongly suggests that the Beehiiv platform architecture is highly optimized for technical performance, actively forcing browser-level interventions to ensure a rapid and seamless initial user experience, which is heavily correlated with higher conversion rates in digital publishing.
Environmental Variables and Operating System Telemetry
At 14:46:16.629, a script identified as global.js executes, outputting a precise piece of environmental telemetry to the console: Platform: Windows [Query_Log]. This entry occurs a mere 29 milliseconds after the initial page load intervention, indicating it is part of the foundational, synchronous JavaScript bundle executed immediately by the browser.
The extraction of operating system data is a standard practice in enterprise web analytics and application delivery. To generate this output, the global.js script most likely queries the navigator.platform or the more modern navigator.userAgentData API natively provided by the browser. Identifying the host operating system allows the web application to conditionally render specific user interface elements, optimize typography for Windows-specific font rendering engines (such as ClearType), or tailor software download prompts appropriately.
Furthermore, this instantaneous environment check acts as a preliminary layer of device fingerprinting. In the context of the highly monetized traffic indicated by the UTM parameters, identifying the operating system assists the enterprise in filtering out non-human bot traffic, validating the authenticity of the ad click, and ensuring that the analytics payload generated later in the session contains highly accurate demographic hardware data. The speed at which this script executes confirms its prioritization in the application’s critical rendering path [Query_Log].
Document Object Model Rendering Anomalies and Vector Graphic Standardization
Between the narrow chronological window of 14:46:16.638 and 14:46:16.643, the console registers three consecutive, identical warnings regarding a fundamental failure in DOM parsing: Error: <svg> attribute height: Expected length, “auto” [Query_Log]. These recurring errors highlight a profound architectural discrepancy between modern Cascading Style Sheets (CSS) responsive design logic and the incredibly strict validation requirements of the Scalable Vector Graphics (SVG) technical specification.
| Timestamp | Source | Error Context | Diagnostic Implication |
| 14:46:16.638 | Line 880 | SVG Height Error | First instance of non-compliant XML geometry in the DOM tree. |
| 14:46:16.638 | Line 902 | SVG Height Error | Second instance, executing simultaneously, indicating a reused component. |
| 14:46:16.643 | Line 985 | SVG Height Error | Third instance, confirming systemic deployment of improperly formatted UI elements. |
XML Validation Strictness within HTML5 Architectures
Scalable Vector Graphics are distinct from traditional raster images (such as JPEGs, WebPs, or PNGs) because they do not contain pixel data. Instead, they are fundamentally mathematically defined geometries, paths, and polygons represented in an Extensible Markup Language (XML) format. When embedded directly into an HTML document (inline SVG), the browser’s primary rendering engine must pause HTML parsing and process the SVG code according to the World Wide Web Consortium (W3C) standards for XML namespaces, which are significantly less forgiving and more rigid than standard HTML parsing.
The error originates from a frontend developer attempting to apply the value “auto” directly to the inline height attribute of an <svg> DOM element [Query_Log]. In modern responsive CSS, applying height: auto; is a ubiquitous and perfectly valid technique utilized to maintain the intrinsic aspect ratio of an element based dynamically on its computed width. However, within the native XML attributes of an <svg> element itself, the height and width attributes strictly require a mathematically definable length value. Acceptable values must be an absolute pixel count (e.g., 250px), a relative percentage of the parent container (e.g., 100%), or a defined coordinate system unit (e.g., 20em).
When the XML parser encounters <svg height=”auto”>, it instantly recognizes that “auto” does not constitute a valid numerical length or coordinate mapping. Consequently, it throws a strict validation error to the console and subsequently ignores the attribute entirely [Query_Log].
Mathematical Implications for Cumulative Layout Shift
The failure to establish explicit, numerically valid dimensions for vector graphics at the DOM level introduces severe systemic risks regarding Cumulative Layout Shift (CLS), a heavily weighted metric within Google’s Core Web Vitals algorithm. When the browser constructs the internal layout tree, it allocates physical screen real estate for elements based on their defined dimensions before they are visually painted.
If the inline height attribute fails XML validation and is stripped by the parser, the browser initially allocates zero vertical space for the SVG element. As the document parsing continues and external, render-blocking CSS stylesheets are eventually downloaded and executed (which may correctly apply the auto height via a CSS class selector rather than an inline attribute), the browser is forced to retroactively recalculate the layout geometry. It must violently expand the SVG to its proper visual size. This localized expansion forces a mathematical recalculation of the position of all subsequent DOM elements, shifting them down the visual viewport.
The severity of a layout shift is calculated mathematically by the browser:

The impact fraction measures how much unstable visual area changes between frames, while the distance fraction measures the greatest distance the unstable element has moved relative to the viewport. The repetition of this specific validation error across three distinct log entries (lines 880, 902, and 985) strongly indicates the presence of a standardized, reusable interface component—such as a navigation icon library, standardized social media sharing links, or primary user interface buttons—that has been improperly configured across the enterprise codebase [Query_Log]. While minor in isolation, these rendering anomalies contribute directly to cumulative performance degradation, negatively impact SEO scores via CLS penalties, and indicate a demonstrable breakdown in frontend automated validation protocols prior to code deployment.
Application State Telemetry and Conditional User Workflows
At 14:46:17.918, the script identified as global.js outputs a highly specific diagnostic state variable: Next Play User: false [Query_Log]. Occurring over a second after the initial page load, this entry provides deep, privileged visibility into the proprietary business logic and session management state machines executed by the Beehiiv application architecture.
The output explicitly acts as a boolean flag, dynamically evaluating the user’s current session parameters, authentication state, or historical engagement profile. The variable nomenclature “Next Play User” likely corresponds to a proprietary platform feature, a specific subscription tier, or a targeted onboarding workflow native to the Beehiiv ecosystem. A boolean value of false confirms multiple potential states: that the current session is entirely unauthenticated (a guest user), represents a newly acquired user who has not yet triggered a specific behavioral threshold, or belongs to an existing user profile that currently lacks the requisite permissions or financial status to access premium “Next Play” features.
The delayed execution of this boolean check at approximately 1.3 seconds after the initial page request demonstrates that the application architecture relies heavily on asynchronous JavaScript execution to determine complex user states, rather than relying solely on monolithic server-side rendering. This modern architectural choice necessitates highly robust client-side routing and reactive components (common in frameworks like React or Vue.js) to adapt the user interface dynamically based on the asynchronous resolution of these backend state variables. By logging this state to the console, engineers can rapidly verify that the conditional rendering logic is properly defaulting to the unauthenticated state for newly acquired, ad-driven traffic [Query_Log].
Statistical Degradation in A/B Testing and Experimentation Infrastructure
Simultaneous with the execution of the application state logic, a critical operational anomaly occurs regarding the site’s client-side experimental framework. At 14:46:17.137, a major intervention is logged by the console: ✨ homepage-h1 (timeout — showing control, NOT tracking in experiment) [Query_Log].
This single, highly detailed log entry encapsulates the incredibly complex interplay between web performance optimization, statistical experimentation integrity, and user experience preservation. The enterprise is clearly utilizing an A/B testing or multivariate testing tool (such as Optimizely, VWO, or a proprietary internal solution) in a continuous effort to mathematically optimize the conversion rate of the primary, most visible headline (homepage-h1) on the landing page.
The Mechanics and Risks of Client-Side Experimentation
In standard client-side A/B testing architectures, an external, highly privileged JavaScript library must be downloaded, parsed, and executed before the browser visually renders the targeted DOM elements to the user. The script’s function is to identify the unique user, assign them to a specific mathematical variant bucket (e.g., Variant A or Variant B) using a pseudo-random hashing algorithm tied to their cookie, and dynamically alter the HTML content of the target headline to match the assigned variant.
To prevent a catastrophic visual glitch known as the Flash of Unstyled Content (FOUC)—a scenario where the original headline renders for a fraction of a second before suddenly and jarringly changing to the variant headline—these experimentation scripts typically employ a synchronous blocking mechanism. This mechanism often injects a temporary CSS overlay that hides the <body> element entirely until the variant is successfully downloaded and applied.
Timeout Thresholds and Statistical Selection Bias
If the user’s network connection is severely degraded, or if the third-party server hosting the experimentation script experiences high latency or an outage, the synchronous blocking mechanism could theoretically prevent the page from rendering indefinitely, resulting in a blank white screen. To mitigate this catastrophic failure state, enterprise testing frameworks implement a strict, non-negotiable timeout threshold (historically configured between 1.5 to 2.5 seconds).
The console log entry explicitly confirms that the experiment script failed to download, parse, and execute within this predetermined mathematical timeout threshold [Query_Log]. Consequently, the framework’s internal fail-safe mechanism was instantly triggered. The browser forcibly aborted the experiment, bypassed the blocking overlay, rendered the default “control” headline, and crucially, explicitly excluded the user from the experimental tracking cohort [Query_Log].
This explicit exclusion is a foundational principle in maintaining statistical integrity and preventing data corruption. In mathematical hypothesis testing, the validity of the results depends entirely on random assignment. If users with inherently slower network connections, older mobile devices, or geographically distant IP addresses were systematically served the control variant due to timeouts, but were still tracked as active participants in the experiment, the resulting dataset would suffer from profound selection bias.
The performance characteristics of the user’s hardware and network would become hidden confounding variables, heavily skewing the results and invalidating the statistical significance of the test. To ensure mathematical rigor (typically targeting a 95% confidence interval), the framework must discard this data point. By explicitly logging NOT tracking in experiment, the system guarantees that the A/B test data remains perfectly uncontaminated by latency-induced anomalies, ensuring that engineering and marketing leadership can trust the final statistical output [Query_Log].
Asynchronous Tracking Architectures and Data Egress
The culmination of the primary application lifecycle occurs precisely at 14:46:20.121 and 14:46:20.123, marked by the sequential loading and initialization of the beehiiv pixel v2.2.0 [Query_Log]. The deployment of this highly specialized pixel represents the definitive transition from content rendering and DOM manipulation to persistent, asynchronous data harvesting.
Evolution and Architecture of the Modern Tracking Pixel
Historically, a “tracking pixel” was a literal 1×1 pixel transparent GIF image embedded directly in an HTML document. When the browser requested the image from the server, the server simply logged the HTTP request headers, capturing the IP address, user agent, and cookies. Modern implementations, however, such as the pixel-v2.js script identified in the forensic log, are significantly more sophisticated and invasive. They are not static images, but rather comprehensive, heavily obfuscated JavaScript libraries designed to autonomously monitor complex client-side behavior across the entire DOM.
The console output carefully delineates a two-step asynchronous execution process:
- Loaded (14:46:20.121): The browser’s background networking thread successfully downloads the JavaScript file from the Beehiiv Content Delivery Network (CDN) and the JavaScript engine (such as V8 in Chrome) parses the syntax [Query_Log].
- Initialized (14:46:20.123): Two milliseconds later, the main thread executes the script, instantiating the core tracking functions. This initialization phase involves reading existing first-party cookies, establishing complex event listener hierarchies on the DOM (tracking mousedown, scroll, and keydown events), and preparing the exfiltration pipeline [Query_Log].
Data Egress and Structured Payload Construction
Once successfully initialized, the Beehiiv pixel is capable of monitoring a vast array of user interactions, including precise scroll depth percentages, multi-axis mouse movements, form interactions, and exact time-on-page metrics. More critically for the enterprise, the pixel is responsible for actively parsing the window.location.href object, collecting all the URL parameters established at the exact beginning of the session (the gclid, utm_campaign=yt_shanik, and dub_id) and packaging them into a highly structured JSON (JavaScript Object Notation) payload.
This formatted payload is then systematically transmitted back to the enterprise database via asynchronous XMLHttpRequest (XHR) or the more modern Fetch API. Frequently, modern pixels utilize the navigator.sendBeacon() method for this egress. The sendBeacon method is specifically designed by browser vendors for telemetry; it ensures that the data is reliably transmitted to the server even if the user precipitously closes the browser tab or navigates away, guaranteeing accurate attribution for the financial ad spend that originated the visit.
The deliberately delayed initialization of the tracking pixel (occurring exactly 3.521 seconds after the initial page request at 14:46:16.600) is highly indicative of a conscious architectural decision to aggressively defer non-essential scripts. By purposefully delaying the execution of the heavy telemetry infrastructure, the enterprise ensures that the primary JavaScript parsing thread remains entirely unblocked during the critical initial visual rendering phase. This trade-off ensures user satisfaction and Core Web Vital compliance while slightly risking data loss if the user bounces before the 3.5-second mark.
Network Resolution Failures and Privacy-Preserving Interventions
The final recorded event in the provided sequence presents a profound shift from successful application execution to a hard, unrecoverable network-level failure. At 14:46:40.556, approximately twenty seconds after the pixel initialization, a request to a third-party domain is violently aborted: static.ads-twitter.com/uwt.js:1 Failed to load resource: net::ERR_NAME_NOT_RESOLVED [Query_Log].
This specific Chromium error code (ERR_NAME_NOT_RESOLVED) is one of the most definitive diagnostic markers in web telemetry forensics. It signifies a catastrophic failure within the Domain Name System (DNS) resolution process, explicitly indicating that the client’s network infrastructure was completely unable to translate the alphanumeric hostname static.ads-twitter.com into a valid, routable IP address.
| Resolution Step | Standard Operation | Failed Operation (ERR_NAME_NOT_RESOLVED) |
| Local Cache | Browser checks cache, finds no record. | Browser checks cache, finds no record. |
| OS Resolver | OS stub queries the recursive resolver. | OS stub intercepts query via local host file or sinkhole. |
| DNS Query | Recursive resolver queries authoritative servers. | Query is aborted or returned as 0.0.0.0 or NXDOMAIN. |
| Connection | TCP handshake initiated with target IP. | Browser throws fatal ERR_NAME_NOT_RESOLVED error. |
The Mechanics of DNS-Level Telemetry Blocking
The ERR_NAME_NOT_RESOLVED error is statistically rarely indicative of a genuine server outage on the part of a massive, redundant infrastructure provider like Twitter (X). Instead, in the context of a known advertising domain (ads-twitter.com), it is the undeniable hallmark signature of active client-side privacy protection. This failure indicates the presence of strict DNS-level ad blocking, a network sinkhole, or a highly aggressive, specialized browser extension [Query_Log].
There are two primary technical mechanisms capable of generating this highly specific failure state within a browser environment:
1. Network Sinkholing and Local DNS Manipulation:
Enterprise network security appliances or consumer privacy tools such as Pi-hole operate directly at the network layer, functioning as a localized, intercepting DNS server. These systems maintain constantly updating, extensive blocklists of known telemetry, advertising, and malware domains. When the operating system’s networking stack requests the IP address for static.ads-twitter.com, the network sinkhole intercepts the request before it reaches the broader internet. Instead of querying the authoritative root servers, it immediately returns an NXDOMAIN (Non-Existent Domain) response or deliberately routes the request to a null IP address (e.g., 0.0.0.0). The browser naturally interprets this intentional nullification as a genuine inability to resolve the name, outputting the observed error [Query_Log].
2. Aggressive Client-Side API Filtering:
Privacy extensions such as uBlock Origin or privacy-focused browser engines (e.g., Brave) utilize deep browser APIs (like chrome.webRequest.onBeforeRequest) to maintain localized filtering rulesets. When the browser’s internal networking stack attempts to initiate the request, the extension evaluates the target URL string against its massive regular expression ruleset. Upon recognizing an advertising domain, the extension actively and forcefully terminates the request at the browser level before a DNS query is ever formulated or transmitted over the physical network interface. In Chromium-based browsers, this internal, artificial termination is frequently surfaced to the console as a simulated DNS resolution failure (ERR_NAME_NOT_RESOLVED) to maintain standard error handling workflows for the underlying web application.
Implications for Cross-Platform Syndication and Retargeting
The definitive failure to load the Twitter (X) Universal Website Tag (uwt.js) has profound, negative implications for the enterprise’s cross-platform retargeting and attribution architecture [Query_Log]. While the initial visit was successfully attributed to a Google Ads campaign via YouTube, the Beehiiv platform architecture was simultaneously attempting to load the Twitter pixel in the background.
This asynchronous loading of multiple trackers is a highly standard enterprise practice known as pixel syndication. Enterprise platforms simultaneously load tracking scripts from multiple advertising networks (Facebook, Twitter, LinkedIn, TikTok). If the user possesses an active session or a third-party tracking cookie on any of those external platforms, the third-party pixel will detect the cookie and silently log the visit. This mechanism allows the enterprise to mathematically retarget the user with highly specific, personalized advertisements on that secondary platform days or weeks later.
Because the HTTP request to static.ads-twitter.com was categorically blocked at the network level prior to execution, Twitter receives absolutely zero telemetry data regarding this specific session. No cookies are read, no IP addresses are logged, and no behavioral data is transferred. The user is effectively rendered completely invisible to the Twitter advertising ecosystem for the duration of this specific interaction. This singular error log highlights the increasing fragmentation and fragility of digital attribution models in the face of widespread consumer privacy interventions, network-level sinkholes, and increasingly strict browser policies.
Synthesis of the Digital Lifecycle
By meticulously aggregating and mathematically analyzing the disparate data points from the chronological console output, a cohesive, deeply detailed narrative of the digital session emerges. This session is characterized by a complex, high-stakes interplay between financial marketing intent, rigorous engineering execution, statistical experimentation, and unyielding user privacy constraints.
The sequence begins with a highly specific, financially motivated inbound event. An enterprise entity—definitively identified as Beehiiv through the subsequent loading of its tracking infrastructure—has strategically invested capital into the Google Ads network. This investment targets specific individuals, demographics, or promotional identifiers via the YouTube platform. The direct outcome of this financial investment is a successful click by a user navigating to a promotional asset specifically identifying the name Shanik, confirming the primary query extraction requirements [Query_Log]. The URL payload is mathematically dense, engineered with massive redundancy to guarantee attribution continuity across multiple network hops, including the integration of a third-party vanity URL shortener (Dub.co).
Upon the initialization of the client’s browser parsing phase, the stringent engineering priorities of the enterprise immediately become apparent. The frontend architecture deliberately delays the loading of heavy, off-screen multimedia resources, natively utilizing browser interventions to mathematically calculate viewport intersections and defer image rendering [Query_Log]. This aggressive, metric-driven optimization strategy is further evidenced by the implementation of a strict, non-negotiable timeout on the client-side A/B testing infrastructure. The system is architected to prefer degrading the statistical purity of an experiment—excluding the user from the cohort entirely—rather than sacrifice the rendering speed of the primary content [Query_Log].
However, this highly sophisticated optimization is sharply contrasted by minor, repetitive developmental oversights within the DOM itself. The repeated rendering errors generated by the invalid SVG height attributes (“auto”) indicate a lack of strict XML validation within the user interface components prior to deployment [Query_Log]. While these XML errors do not critically impact core functionality, they cause micro-frictions in the browser’s layout geometry algorithms, forcing recalculations that counteract some of the performance gains meticulously achieved through lazy loading and script deferral.
Midway through the session, the core financial objective of the web architecture is realized. The proprietary first-party tracking infrastructure (the Beehiiv pixel) successfully downloads, parses, and initializes. It immediately begins capturing the rich, cryptographic telemetry payload delivered by the Google Ads click, securely routing the data back to the enterprise database for complex processing and financial attribution [Query_Log].
The session ultimately concludes with a stark, undeniable demonstration of the limitations of modern digital marketing infrastructure. Despite the successful execution of the primary, first-party tracking systems, secondary attempts to syndicate behavioral data to external advertising networks are abruptly and violently terminated by the user’s localized privacy controls. The definitive failure of the Twitter telemetry script due to a simulated or actual DNS resolution error serves as a hard boundary marker. It delineates the exact mathematical point where enterprise tracking capabilities are utterly neutralized by client-side network defense mechanisms [Query_Log].
Conclusion
The forensic deconstruction of the provided web telemetry sequence yields highly specific answers regarding entity identification while simultaneously revealing the deep architectural and mathematical complexities of modern enterprise web platforms.
Addressing the primary extraction directive: the analytical findings definitively identify the managing enterprise infrastructure as Beehiiv, evidenced by the explicit, chronological initialization of its proprietary tracking script. Concurrently, the unique identity marker targeted by this specific network request is isolated as Shanik, extracted from the vendor-agnostic UTM parameters utilized to govern the Google Ads and YouTube promotional campaign [Query_Log].
Beyond these immediate identifiers, the log trace exposes a highly robust, aggressively optimized web architecture that actively balances Core Web Vital performance with stringent data harvesting requirements. The system demonstrates advanced utilization of algorithmic browser interventions to maintain rapid visual rendering, enforces strict mathematical latency thresholds to protect user experience during statistical experimentation, and employs highly resilient first-party data capture mechanisms. However, the simultaneous presence of minor DOM layout geometry anomalies and the absolute defeat of third-party syndication attempts underscore the continuous, volatile friction between web development standards, enterprise tracking imperatives, and the rapidly evolving landscape of client-side privacy enforcement.
