1. Fundamentos da Arquitetura do Sistema Nacional de Informações Criminais (ePol-SINIC)
A infraestrutura de segurança pública de um país de dimensões continentais exige uma engenharia de dados capaz de unificar registros fragmentados e, simultaneamente, fornecer respostas em tempo real para a sociedade civil e para as forças de persecução penal. No Brasil, esse pilar de integração é materializado pelo Sistema Nacional de Informações Criminais (SINIC), administrado pela Polícia Federal. O SINIC opera como um imenso barramento de dados, consolidando informações provenientes das Polícias Federal, Rodoviária Federal, Civis e Penais, além de absorver decisões de todas as esferas do Poder Judiciário (Estadual, Federal e Eleitoral). A recente modernização desta plataforma culminou no sistema ePol-SINIC, um ecossistema projetado para substituir arquiteturas legadas e unificar a gestão de históricos criminais individuais sob um modelo estritamente relacional e de alta disponibilidade.
O desafio central de arquiteturas como o ePol-SINIC não reside primariamente no volume de armazenamento, mas na modelagem de um motor de busca que consiga lidar com a entropia e a despadronização crônica da identificação civil brasileira. Diferentemente de sistemas bancários ou tributários, onde uma chave primária forte e universal (como o Cadastro de Pessoas Físicas – CPF) é onipresente e de preenchimento rigoroso, o ecossistema de persecução penal frequentemente lida com indivíduos não documentados, portadores de múltiplas identidades (falsidade ideológica) ou registrados sob grafias precárias. Como resultado direto dessa realidade demográfica, o sistema não pode exigir que o usuário forneça um conjunto absoluto de chaves primárias inalteráveis para emitir um documento.
A interface pública do sistema, responsável pela emissão da Certidão de Antecedentes Criminais (CAC) via internet para fins civis , foi deliberadamente arquitetada sob o paradigma da “busca tolerante”. Em vez de forçar o cidadão a possuir toda a documentação civil em perfeita sincronia com a base de dados, a API do formulário web aceita um espaço combinatório de inputs flexíveis. Existe um bloco de campos de natureza obrigatória (hard constraints), essenciais para qualquer tentativa mínima de indexação difusa, e um extenso rol de variáveis binárias opcionais que o usuário pode fornecer para afunilar a pesquisa.4
A compreensão de como o backend processa essas variáveis transcende a simples engenharia de software; ela adentra o campo da jurimetria e do Direito Administrativo. Cada vez que o sistema processa um input e falha ao desambiguar a identidade do requisitante em relação a um indivíduo com histórico criminal real — o clássico fenômeno da homonímia —, a emissão automatizada do documento de “Nada Consta” é interrompida. O cidadão é então notificado, por meio da geração de um protocolo, de que deve comparecer fisicamente a uma unidade descentralizada da Polícia Federal para auditoria documental manual, um processo que pode levar dias para ser concluído. Essa fricção sistêmica gera repercussões severas na vida civil, desde a perda de oportunidades de emprego até a propositura de ações indenizatórias por dano moral contra o Estado.5
Portanto, dissecar a lógica combinatória booleana que rege os formulários do SINIC, mapear o roteamento do algoritmo de busca fonética empregado para normalizar essas strings e cruzar essa mecânica com a atual jurisprudência de proteção de dados (LGPD) e responsabilidade civil revela a verdadeira anatomia do risco jurídico-tecnológico enfrentado pelo Estado.
2. Topologia de Dados Relacionais: O Registro Federal (RF) e o Boletim Individual Criminal (BIC)
O sucesso da arquitetura de desambiguação do ePol-SINIC depende da estrita separação entre a identidade civil do indivíduo e os eventos jurídicos que compõem o seu histórico. No modelo de dados do sistema, essa separação é implementada por meio de dois indexadores hierárquicos: o Registro Federal (RF) e o Boletim Individual Criminal (BIC). A relação entre eles é de cardinalidade 1:N (um para muitos), formando o alicerce de todas as queries de busca.
O Registro Federal (RF) atua como o nó raiz biográfico. Ele é o identificador único nacional de uma pessoa física dentro do ecossistema da Polícia Federal. No novo padrão estabelecido pelo ePol-SINIC, o RF é composto por 14 dígitos (por exemplo, 1.2023.000.000.158), embora o sistema mantenha indexação e compatibilidade retroativa (legacy mode) para buscas utilizando o antigo formato de 8 dígitos. A regra de ouro da modelagem é a unicidade absoluta: um ser humano deve possuir apenas um Registro Federal, no qual são ancorados todos os seus dados qualificativos consolidados — nome, nome da mãe, nome do pai, data de nascimento, naturalidade, informações sobre documentos, endereços e indicativos de existência de perfis biométricos no sistema ABIS (Automated Biometric Identification System).
Subordinado estruturalmente ao Registro Federal está o Boletim Individual Criminal (BIC). O BIC é o vetor que materializa a passagem criminal, o fato jurídico em si. Quando um indivíduo é indiciado em um inquérito policial ou torna-se réu em um processo judicial penal, um novo BIC é gerado e vinculado ao seu RF. Consequentemente, uma pessoa que cometeu três delitos distintos em épocas diferentes possuirá apenas um RF, mas terá três numerações de BIC associadas a essa raiz. A alimentação desses boletins é estruturada através da árvore hierárquica de Tipos Penais; o operador do sistema cadastra a ocorrência selecionando sequencialmente a Lei, o Artigo, o Parágrafo, o Inciso e a Alínea, o que garante a uniformidade taxonômica de crimes em todo o território nacional.
Essa topologia dita o comportamento do motor de busca ao processar o formulário da Certidão de Antecedentes Criminais (CAC). Quando a API recebe o payload de dados submetido pelo cidadão, o comando SQL executado no backend não realiza uma varredura direta por crimes (BICs). A primeira etapa da transação foca exclusivamente na tabela de Registros Federais (RFs). A engine tenta encontrar um RF que se alinhe perfeitamente às chaves fornecidas no formulário.
Se essa busca primária retornar um conjunto vazio (Nenhum RF encontrado), a aplicação assume instantaneamente que o indivíduo é desconhecido pelo sistema prisional/criminal federal e aciona a emissão automática do certificado negativo com a chancela de “NADA CONSTA”.3
Entretanto, se a query localizar um (ou vários) RFs correspondentes, a API entra na segunda fase da verificação: a varredura dos BICs atrelados àquele RF. Nesse estágio, o sistema analisa os andamentos processuais. A certidão pública de antecedentes para fins civis é programada para retornar informações positivas (“CONSTA”) apenas e estritamente quando houver registro de decisão condenatória com trânsito em julgado, operando em conformidade com o princípio da presunção de inocência. Todavia, por uma questão de política de segurança, a Polícia Federal não emite certidões positivas de forma automatizada pela internet. Caso exista um histórico confirmado, ou caso a query primária retorne múltiplos RFs homônimos que os algoritmos de desempate (tie-breakers) não consigam resolver, a API trava o fluxo digital. Emite-se um número de protocolo e uma mensagem genérica orientando o usuário a buscar o atendimento presencial para a confirmação de identidade.
É precisamente na mecânica de localização do RF que a robustez do algoritmo de busca fonética se faz imperativa, dada a já mencionada impossibilidade de se confiar em buscas de correspondência exata (exact match) no contexto linguístico e civil brasileiro.
3. O Motor de Busca Heurístico: A Falência do Soundex e a Ascensão do BuscaBR
A integridade operacional do ePol-SINIC repousa sobre a sua capacidade de abstrair erros ortográficos nas strings de entrada. No Brasil, o mesmo nome pode ser grafado de dezenas de formas distintas. “Luiz” e “Luis”, “Tereza” e “Teresa”, “Wellington” e “Uelington”, ou casos de erros cartorários severos como “Maicom” para “Michael”. Em bancos de dados relacionais tradicionais, uma consulta básica do tipo WHERE nome = ‘Wellington’ descartaria silenciosamente os registros grafados como “Uelington”, gerando o pior cenário possível para a segurança pública: o falso negativo (a emissão de uma certidão limpa para um indivíduo com mandado de prisão ativo). Para suplantar esta limitação, a engenharia de dados utiliza a busca fonética difusa.
Nos primórdios da informatização de grandes bancos corporativos e governamentais (como os estruturados em Oracle SGBD), o padrão de mercado era a utilização do algoritmo SOUNDEX.8 Desenvolvido nos Estados Unidos em 1918 por Robert Russell e Margaret Odell, o SOUNDEX foi pioneiro na tentativa de codificar as palavras de acordo com seus fonemas para indexação de censos populacionais.9 A rotina do SOUNDEX mapeia strings atribuindo a primeira letra do nome seguida de três dígitos que representam grupos consonantais da língua inglesa (por exemplo, B, F, P e V recebem o valor 1; C, G, J, K, Q, S, X, Z recebem 2).9 Vogais, assim como as letras H, W e Y, são ignoradas após a primeira posição.9
Embora eficaz para o idioma anglo-saxônico, a aplicação do SOUNDEX à língua portuguesa gera distorções intoleráveis.8 O idioma português possui uma complexidade vocálica e uma dependência silábica que o algoritmo americano destrói. Por exemplo, a letra “C” seguida de “A/O/U” tem som velar de /k/ (“Coca”), mas seguida de “E/I” tem som fricativo de /s/ (“Coce”). O SOUNDEX atribui o mesmo código C200 para ambas as palavras, forçando colisões espúrias no banco de dados.9 Pior ainda, o SOUNDEX é sensível à letra inicial, o que significa que as palavras foneticamente idênticas “Walter” (W436) e “Valter” (V436) recebem hashes totalmente diferentes e não são cruzadas nas queries.9 Ademais, a ausência de tratamento para regionalismos (como a “comeno” em vez de “comendo”, ou a confusão entre “L” e “R” em encontros consonantais, como “Celebro” e “Cérebro”) faz com que o algoritmo internacional comprometa severamente a assertividade da persecução penal.9
Para resolver este impasse arquitetural crítico, pesquisadores brasileiros e engenheiros de software desenvolveram adaptações específicas para a língua portuguesa, consolidando-se no mercado governamental algoritmos como o BuscaBR.8 Incorporado como função PL/SQL em instâncias Oracle e adaptado para diversos frameworks modernos, o BuscaBR atua como um pipeline de normalização fonética estrita que intercepta os parâmetros de entrada (“Nome” e “Nome da mãe”) antes que eles alcancem os índices do banco de dados.8
A execução heurística do algoritmo BuscaBR é composta por seis regras sequenciais que limpam a entropia semântica da string:
- Conversão de Caixa (Uppercase): A string é inteiramente convertida para letras maiúsculas. Isso evita que falhas de collation case-sensitive no banco diferenciem “Silva” de “SILVA”.10
- Supressão de Diacríticos: O algoritmo remove todos os acentos das vogais (agudos, circunflexos, tils e crases). Elimina-se a divergência gerada por omissão de acento em formulários preenchidos às pressas (“João” converte-se em “Joao”, “Efigênia” em “Efigenia”).9
- Matriz de Substituição Consonantal Fonêmica: É a essência do BuscaBR. Letras que causam confusão ortográfica devido a sons idênticos são uniformizadas por tabelas de de-para baseadas na fonologia do português. Consoantes labiodentais, sibilantes e palatais complexas (como os dígrafos CH, LH, NH e a letra X, que pode assumir múltiplos sons dependendo da posição) são normalizados.9 C, Q e K tornam-se representações únicas, neutralizando estrangeirismos.
- Ablação de Terminações Verbais e Plurais (M, R, S): Uma inovação crucial para o Brasil. O algoritmo decepa sumariamente as letras M, R e S quando posicionadas no final das palavras. A justificativa empírica é que o uso inadequado do plural (“Dasilvas” vs “Dasilva”) e do infinitivo, bem como erros de nasalidade final (“Dizendo” registrado como “Dizeno”), são prolíficos nos registros de populações de baixa escolaridade.9 Remover essas terminações funde as variantes na mesma raiz fonética.
- Extermínio Vocálico e Letras Mudas: Diferente do Soundex, que mantém a primeira letra, o BuscaBR, após aplicar a Regra 3 (que resolve as dependências consonantais), varre e elimina todas as vogais e as consoantes inertes (H, W e Y) de todas as posições da string, por não possuírem mais relevância estrutural no esqueleto fonético da palavra normalizada.10
- Desduplicação (Colapso de Sequências): Qualquer sequência resultante onde duas letras ou símbolos idênticos fiquem adjacentes é reduzida a uma única ocorrência (por exemplo, os duplos “SS”, “RR” ou “LL” de grafias antigas são colapsados em “S”, “R”, “L”).10
Na prática da emissão da Certidão de Antecedentes Criminais, quando um cidadão insere “Gleyce Kelly” no formulário e a sua passagem criminal no ePol-SINIC está grafada como “Gleice Keli”, o pipeline do BuscaBR assegura que ambas as strings resultem no mesmo hash hash indexado. A consulta WHERE phonet(nome) = hash_entrada retornará verdadeiro. A desvantagem intrínseca dessa robustez é a ampliação orgânica do recall (revocação) da query: o motor encontrará muito mais correspondências, exacerbando o fenômeno da colisão de hashes entre pessoas diferentes — o Falso Positivo por homonímia.13 É para combater esse efeito colateral matemático que o sistema exige o refinamento da query através da exploração do espaço combinatório booleano restrito dos formulários de entrada.
4. Formalização do Espaço Combinatório e Lógica Booleana Restrita do SINIC
O formulário web do SINIC é o portal de entrada para o motor de inferência fonética. A arquitetura de “busca tolerante” obriga o sistema a lidar com cenários onde o usuário possui vasto arcabouço documental e cenários de precariedade de identificação. Do ponto de vista da teoria dos conjuntos e da lógica booleana, o formulário é um vetor de parâmetros que alimenta o construtor da query no banco de dados.
Para garantir que a busca difusa tenha um alicerce mínimo (baseline), a aplicação impõe uma restrição rígida (hard constraint) no front-end e no back-end.4 Nenhum processamento é autorizado sem o fornecimento obrigatório de três dados fundamentais:
- Nome Completo do Indivíduo (âncora de busca principal).
- Data de Nascimento (filtro determinístico secundário).
- Nome da Mãe (âncora de busca fonética secundária, admitindo a sinalização explícita de “mãe ignorada/desconhecida”, que é tratada como um estado semanticamente válido para a engine).
Com a fundação estabelecida, o grau de precisão da query é refinado pelas variáveis independentes opcionais (soft constraints). Podemos modelar esse ambiente tratando cada campo complementar como uma variável binária, onde 0 representa a ausência de input (nulo) e 1 representa a presença do input fornecido pelo cidadão. Os sete eixos independentes são:
- CPF
- Nacionalidade
- País de Nascimento
- Unidade da Federação (UF) de Nascimento
- Município de Nascimento
- Nome do Pai
- Documento Adicional (Tipo e Número, atuando em par)
Em um universo combinatório estatístico bruto, onde sete variáveis podem assumir dois estados independentes, teríamos combinações absolutas de input. No entanto, o design de esquemas de banco de dados relacionais e a taxonomia geográfica mundial impõem dependências lógicas internas. O preenchimento da hierarquia de nascimento obedece a uma árvore de domínios restrita: é impossível validar semanticamente a presença de um “Município” se a “UF” (estado) e o “País” não estiverem presentes, assim como é inválido ter uma “UF” sem um “País” declarado. Logo, o trio {País, UF, Município} não atua como três variáveis autônomas que geram
cenários, mas sim como um bloco geográfico de profundidade escalonada, limitando-se a exatamente 4 estados válidos:
- Estado 0: Bloco totalmente ausente (O cidadão omite os dados de nascimento).
- Estado 1: Apenas o País de Nascimento é fornecido (Comum para estrangeiros).
- Estado 2: País + UF de Nascimento.
- Estado 3: País + UF + Município (Estrutura de naturalidade completa).
Ao injetar essa dependência hierárquica na equação geral do espaço de variáveis, a recontagem do total de combinações que o compilador de query do SINIC precisa suportar resulta na seguinte formulação matemática:

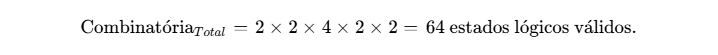
Essa constatação evidencia a sofisticação silenciosa da infraestrutura pública. A API do ePol-SINIC não exige um formato único; ela possui um Query Execution Plan projetado para rotear e processar 64 “subconjuntos coerentes” de identificação civil de forma polimórfica, aplicando o algoritmo BuscaBR aos campos pertinentes e usando os demais campos ativados para realizar o tie-break (desempate) entre os milhares de Registros Federais que a colisão fonética inevitavelmente retornará.
5. Enumeração Exaustiva da Matriz Vetorial de Inputs (As 64 Combinações)
A compreensão das falhas de emissão e da geração de falsos positivos (que exigirão deslocamento presencial do cidadão) requer o mapeamento completo destas 64 formas de interação sistêmica. Cada subconjunto de vetores dita o limiar de confiança (threshold) com o qual o sistema aceitará liberar a Certidão online de Nada Consta.
Para fins de análise técnica e jurimétrica, o espaço combinatório é cindido ao meio pela presença ou ausência do CPF (Cadastro de Pessoas Físicas), uma chave primária forte o suficiente para alterar a rota algorítmica de uma Busca de Varredura Heurística (Fuzzy Scan) para uma Busca de Índice Determinística (Index Seek). O mapeamento a seguir codifica o vetor de entrada usando a notação [CPF][NAC][PAI].
Grupo A: A Fronteira Fonética Difusa — Cenários Sem CPF (Combinações 01 a 32)
Este quadrante congrega os 32 cenários nos quais a variável CPF está inativa (0). Nestas condições, o SINIC não possui nenhum indexador numérico universal de alta confiança para realizar o cruzamento inicial. O backend recai inteiramente sobre a engine do algoritmo BuscaBR processando o Nome e o Nome da Mãe. O risco de colisão homonímica neste quadrante varia do Crítico (exigindo intervenção humana na esmagadora maioria das vezes) ao Baixo (quando as outras chaves são suficientes para quebrar a ambiguidade).
Bloco A1: Extrema Baixa Densidade de Dados (Bloco Geográfico = 0)
A naturalidade é ignorada pelo requisitante. A API busca desambiguar baseando-se apenas na filiação paterna, nacionalidade ou documentos não-padronizados.
| ID | Codificação Lógica | Vetor de Identidade (Além dos Obrigatórios: Nome + Mãe + Dt Nasc) | Nível de Risco de Colisão (Homonímia) |
| 1 | “ | Apenas o baseline restrito (Nenhum campo opcional preenchido). | CRÍTICO. Altíssima taxa de falsos positivos. |
| 2 | “ | Baseline + Nacionalidade informada. | CRÍTICO. Nacionalidade não filtra o universo nacional efetivamente. |
| 3 | “ | Baseline + Nome do Pai. | ELEVADO. Exige dupla execução do BuscaBR. |
| 4 | “ | Baseline + Tipo/Número de Documento secundário (ex: RG estadual). | MÉDIO. Depende do estado emissor do RG não conflitante. |
| 5 | “ | Baseline + Nacionalidade + Nome do Pai. | ELEVADO. |
| 6 | “ | Baseline + Nacionalidade + Documento secundário. | MÉDIO. |
| 7 | “ | Baseline + Nome do Pai + Documento secundário. | BAIXO A MÉDIO. Filtro paramétrico forte. |
| 8 | “ | Baseline + Nacionalidade + Nome do Pai + Documento secundário. | BAIXO A MÉDIO. |
Bloco A2: Filtro Geográfico de Nível 1 (Bloco Geográfico = 1: Apenas País)
Cenário frequentemente acionado por requisitantes estrangeiros naturalizados ou cidadãos que ignoram a cidade de origem. A redução do espectro de busca é modesta.
| ID | Codificação Lógica | Vetor de Identidade (Além dos Obrigatórios: Nome + Mãe + Dt Nasc) | Nível de Risco de Colisão (Homonímia) |
| 9 | “ | Baseline + País de Nascimento. | CRÍTICO. Se for “Brasil”, não filtra o universo interno. |
| 10 | “ | Baseline + Nacionalidade + País. | CRÍTICO. |
| 11 | “ | Baseline + Nome do Pai + País. | ELEVADO. |
| 12 | “ | Baseline + Documento + País. | MÉDIO. |
| 13 | “ | Baseline + Nacionalidade + Pai + País. | ELEVADO. |
| 14 | “ | Baseline + Nacionalidade + Documento + País. | MÉDIO. |
| 15 | “ | Baseline + Pai + Documento + País. | BAIXO. Alta especificidade indireta. |
| 16 | “ | Baseline + Nacionalidade + Pai + Documento + País. | BAIXO. |
Bloco A3: Filtro Geográfico de Nível 2 (Bloco Geográfico = 2: País + UF)
A inclusão da Unidade da Federação é o primeiro limitador estatístico de alto impacto contra falsos positivos sistêmicos, reduzindo regionalmente o hash do BuscaBR.
| ID | Codificação Lógica | Vetor de Identidade (Além dos Obrigatórios: Nome + Mãe + Dt Nasc) | Nível de Risco de Colisão (Homonímia) |
| 17 | “ | Baseline + País + UF de Nascimento. | ELEVADO. Homonímia regional ainda provável em estados grandes (ex: SP, MG). |
| 18 | “ | Baseline + Nacionalidade + País + UF. | ELEVADO. |
| 19 | “ | Baseline + Nome do Pai + País + UF. | MÉDIO. Forte amarração demográfica. |
| 20 | “ | Baseline + Documento + País + UF. | BAIXO. |
| 21 | “ | Baseline + Nacionalidade + Pai + País + UF. | MÉDIO. |
| 22 | “ | Baseline + Nacionalidade + Doc + País + UF. | BAIXO. |
| 23 | “ | Baseline + Pai + Doc + País + UF. | MUITO BAIXO. |
| 24 | “ | Estrutura quase plena, omitindo apenas Município. | MUITO BAIXO. |
Bloco A4: Filtro Geográfico Pleno (Bloco Geográfico = 3: País + UF + Município)
A naturalidade completa permite ao SINIC pinçar o registro no contexto cartorário mais estreito possível. O risco de colisão fonética cai drasticamente.
| ID | Codificação Lógica | Vetor de Identidade (Além dos Obrigatórios: Nome + Mãe + Dt Nasc) | Nível de Risco de Colisão (Homonímia) |
| 25 | “ | Baseline + Nascimento Completo (País, UF, Município). | MÉDIO. Homônimos exatos nascidos na mesma cidade são raros. |
| 26 | “ | Baseline + Nascimento Completo + Nacionalidade. | MÉDIO. |
| 27 | “ | Baseline + Nascimento Completo + Pai. | BAIXO. |
| 28 | “ | Baseline + Nascimento Completo + Documento. | BAIXO. |
| 29 | “ | Baseline + Nascimento Completo + Nacionalidade + Pai. | BAIXO. |
| 30 | “ | Baseline + Nascimento Completo + Nacionalidade + Doc. | BAIXO. |
| 31 | “ | Baseline + Nascimento Completo + Pai + Documento. | INEXPRESSIVO. Altíssima fidelidade. |
| 32 | “ | Máxima densidade de dados civis alcançável sem um CPF. | INEXPRESSIVO. Emissão garantida se limpo. |
Grupo B: A Âncora Determinística — Cenários Com CPF (Combinações 33 a 64)
As 32 combinações deste quadrante são os reflexos especulares do Grupo A, mas com a chave CPF ativada (1). A inserção do CPF na query altera o modelo de avaliação de risco do SINIC. A heurística fonética deixa de ser o mecanismo de busca primário e passa a atuar como um Sanity Check (checagem de integridade) de dupla camada.
O sistema fará a busca no índice único de CPFs. Se o CPF possuir um Registro Federal associado com um BIC criminal e o nome fonético for congruente com o input, a restrição de emissão é certa. Contudo, o sistema incorpora uma restrição externa formidável: a integração com o banco de dados da Receita Federal do Brasil (RFB). Se o usuário fornece o CPF correto, mas o Nome submetido no formulário divergir (mesmo que ligeiramente além da margem fonética de tolerância) do nome cadastrado na base da Receita, a transação é flagrada como suspeita de falsidade ideológica ou fraude. A API do SINIC trava a emissão online imediatamente, mesmo que a ficha seja limpa.
Portanto, nas combinações de 33 a 64, o risco não é de encontrar um “homônimo criminal”, mas de “divergência burocrática intersistêmica” que obriga a ida ao balcão da Polícia Federal.
| ID Range | Codificação Lógica Base | Roteamento Backend Primário | Avaliação de Risco e Comportamento |
| 33 a 40 | [X][X][X] | Validação CPF + Receita -> Verificação RF. | Risco Baixíssimo. Omissão de dados geográficos não impacta devido à força da chave primária. |
| 41 a 48 | [X][X][X] | Validação CPF + Receita -> Verificação RF. | Risco Baixíssimo. |
| 49 a 56 | [X][X][X] | Validação CPF + Receita -> Verificação RF. | Risco Nulo. Apenas divergências cadastrais hard bloqueiam. |
| 57 a 64 | [X][X][X] | Validação CPF + Receita -> Verificação RF. | Risco Nulo. A combinação 64 (“) é o preenchimento absoluto exaustivo. Garantia matemática de processamento sem ruídos. |
6. O Fluxo de Roteamento de Backend (Pseudocódigo Arquitetural)
Para transpor as 64 matrizes combinatórias descritas na seção anterior para a prática da engenharia de software, é útil vislumbrar o Execution Plan da aplicação na forma de um pseudocódigo. O backend não utiliza 64 condicionais if/else, mas roteia o payload por meio de uma árvore de decisão inteligente que processa as chaves fortes (CPF) primeiro, e só invoca o afunilamento heurístico do BuscaBR se necessário para resolver as combinações do Grupo A.
Python
def emitir_cac(nome, dt_nasc, mae, cpf=None, nac=None, nasc_bloco=0, pai=None, doc=None):
# Validação de Hard Constraints (Interceptação no Frontend/Backend)
if not (nome and dt_nasc and mae):
return abort(400, “Campos obrigatórios ausentes. Rejeição estrutural.”)
# Fase 1: Normalização Fonética Obrigatória (Algoritmo BuscaBR)
hash_nome = BuscaBR(nome)
# Suporte lógico para ‘Mãe Desconhecida/Ignorada’
hash_mae = BuscaBR(mae) if mae.upper() not in else “NULO”
# Fase 2: Roteamento Determinístico (Grupo B: Combinações 33 a 64)
if cpf:
# Cross-check de integridade com API externa (Prevenção à Fraude)
if not receita_federal.validar_titularidade(cpf, nome, dt_nasc):
return “Bloqueio: Divergência de titularidade na base da Receita Federal. Compareça a uma unidade PF.”
# Index Seek (Complexidade O(1) ou O(log N))
rf_encontrado = db.query(“SELECT id, nome_fonetico FROM Registro_Federal WHERE cpf =?”, cpf)
if rf_encontrado:
# Validação Sanity Check para prevenir inserção maliciosa de CPF alheio
if rf_encontrado.nome_fonetico == hash_nome:
return checar_bic_e_emitir(rf_encontrado.id)
else:
return “Bloqueio: Conflito Interno de Identificação. Compareça à PF.”
else:
# CPF não possui Registro Federal no SINIC.
# Dupla checagem: o indivíduo pode ter RF antigo sem CPF cadastrado.
candidatos = realizar_busca_fonetica_pura(hash_nome, hash_mae, dt_nasc)
if candidatos.count > 0:
return “Bloqueio: Possível homonímia em base legada sem CPF. Compareça à PF.”
return “Emissão Automática: NADA CONSTA”
# Fase 3: Roteamento Fonético Difuso (Grupo A: Combinações 1 a 32)
else:
# Full Index Scan fonético. Complexidade algorítmica elevada.
candidatos_rf = db.query(“””
SELECT * FROM Registro_Federal
WHERE fonetica_nome =? AND fonetica_mae =? AND data_nascimento =?
“””, hash_nome, hash_mae, dt_nasc)
if candidatos_rf.count == 0:
# Nenhum homônimo ou suspeito encontrado
return “Emissão Automática: NADA CONSTA”
elif candidatos_rf.count == 1:
# Um alvo encontrado. Confiança média. Necessita de tie-break opcional.
rf = candidatos_rf.first()
# Avalia se os campos opcionais preenchidos confirmam ou negam a identidade
score = calcular_confianca_tie_break(rf, nac, nasc_bloco, pai, doc)
if score >= THRESHOLD_ACEITACAO:
return checar_bic_e_emitir(rf.id)
else:
return “Bloqueio: Informações insuficientes para garantir identidade segura. Protocolo gerado.”
else:
# Múltiplos RFs encontrados. Alta colisão fonética (Homonímia Genuína).
rf_refinado = aplicar_filtros_restritivos(candidatos_rf, nac, nasc_bloco, pai, doc)
# Se os campos opcionais reduzirem os múltiplos RFs a exatamente 1 com alta confiança
if rf_refinado.count == 1 and rf_refinado.score >= THRESHOLD_ALTO:
return checar_bic_e_emitir(rf_refinado.first().id)
# A ambiguidade persiste. Risco altíssimo de falso positivo na emissão de certidão criminosa.
return “Bloqueio de Segurança: Homonímia Múltipla Irresolvível Digitalmente. Compareça à PF.”
def checar_bic_e_emitir(rf_id):
# Roteamento final após resolução de identidade
crimes = db.query(“SELECT * FROM BIC WHERE rf_id =? AND status = ‘TRANSITO_EM_JULGADO'”, rf_id)
if crimes:
return “Emissão Negada Online: Registros Encontrados (Certidão Positiva apenas presencialmente)”
return “Emissão Automática: NADA CONSTA”
A observação deste fluxo computacional materializa a diretriz máxima do SINIC: a proteção contra a emissão de um falso atestado de integridade para um procurado pela justiça se sobrepõe ao conforto digital do usuário. Em caso de ruído estatístico — especialmente nos cenários das combinações 1 a 10 —, o sistema delega a resolução para a perícia humana presencial. O subproduto indesejado desse conservadorismo programático é a eclosão do passivo de risco jurídico do Estado e do setor privado.
7. Matriz de Risco Jurídico: Jurimetria, Responsabilidade Civil e a Doutrina do Falso Positivo
Na interface entre a Ciência de Dados e o Direito (Jurimetria), os “falsos positivos de segurança” gerados pelo algoritmo do ePol-SINIC (o fato da API retornar “Protocolo: Compareça a uma unidade” em vez de emitir o documento online por conflito de homonímia) transformam-se rapidamente em disputas judiciais sobre perdas e danos. Cidadãos de ficha limpa que, em virtude da precariedade documental da combinação preenchida, colidem no sistema com o RF de criminosos que compartilham do mesmo nome e data de nascimento, sofrem atrasos em admissões de emprego, impedimentos em licitações e, não raro, constrangimentos severos em abordagens policiais ordinárias.14
A Responsabilidade Civil do Estado (Ação Indenizatória)
A jurisprudência brasileira lida amplamente com os reflexos de bancos de dados governamentais falhos ou insuficientes. A tese predominante na doutrina e consagrada nas Cortes Superiores estabelece que o Estado detém responsabilidade civil de natureza objetiva, amparada pela teoria do risco administrativo prevista na Constituição Federal, frente aos danos causados por “erros da atividade administrativa judiciária” ou ineficiência dos bancos de identificação.5
O Tribunal de Justiça tem prolatado sentenças onde o dano moral derivado de uma confusão grosseira de identidade no sistema prisional ou investigativo — quando faltam as diligências mínimas para desambiguar a autoria de um BIC, expondo homônimos ao constrangimento criminal — é concebido como dano in re ipsa (dano presumido), ou seja, a vítima está dispensada de produzir prova profunda sobre o abalo psicológico.5
De forma ainda mais incisiva quanto aos impactos vitais da homonímia, o Superior Tribunal de Justiça (STJ), no julgamento do REsp 1.962.674-MG (Terceira Turma, julgado em 2022), deferiu pedido autônomo e excepcional de retificação de registro civil de um indivíduo fundamentado exclusivamente no fato de possuir homônimo respondendo a processo criminal em outro estado da federação.14 A Corte assentou que a contaminação cruzada promovida por bases de dados de segurança nacional gerava um “constrangimento capaz de configurar o justo motivo” para a alteração imutável do nome.14 Esse precedente expõe o altíssimo custo que a imprecisão combinatória da identificação impõe à sociedade civil.
Risco Corporativo: O Dano Moral pela Exigência de CAC
Se o Estado responde objetivamente pelos gargalos de emissão, o setor privado navega em águas ainda mais turbulentas quando passa a exigir os produtos do SINIC de seus quadros. Historicamente, muitas corporações brasileiras embutiram nos seus processos de compliance e recursos humanos o envio forçado dos dados dos candidatos (nos moldes das 64 combinações da Polícia Federal) para “limpar a base”.
O Tribunal Superior do Trabalho (TST), visando frear essa prática, exarou decisão vinculante através do Incidente de Resolução de Demandas Repetitivas (IRR), convertido no Tema 1.16 A Corte definiu rigidamente a fronteira legal da checagem de antecedentes. O Tema 1 dita que a exigência da Certidão de Antecedentes Criminais de um candidato a emprego é ato ilícito discriminatório, configurando dano moral in re ipsa passível de indenização — pouco importando se o candidato possui ou não condenações —, salvo se amparada em expressa disposição legal ou em casos inerentes ao grau de fidúcia da atividade (exemplos delineados pela corte: trabalhadores em creches e asilos cuidando de vulneráveis, bancários manuseando numerário, empregados da agroindústria com ferramentas letais, e motoristas rodoviários de carga).16
Uma empresa que exija os dados das combinações do ePol-SINIC (notadamente sem o consentimento qualificado) para filtrar auxiliares administrativos, portanto, absorve uma presunção de culpa absoluta aos olhos do TST.16
8. Tratamento de Dados de Segurança Pública sob a Égide da LGPD
A imersão na arquitetura combinatória do SINIC deve, necessariamente, contemplar a regulação da Lei Geral de Proteção de Dados (LGPD – Lei nº 13.709/2018). Historicamente, bancos de dados penais operavam sob uma égide de sigilo compartimentado ineficiente; hoje, exigem um desenho de software blindado. Dados de infrações penais ou condenações criminais transbordam o mero cadastro biográfico, inserindo-se na proteção rigorosa conferida a perfis de alta sensibilidade.20
Em seu Artigo 4º, a LGPD explicitamente excepciona de seu crivo punitivo administrativo as atividades realizadas com propósitos exclusivos de segurança pública, defesa nacional e persecução penal.21 O ecossistema do SINIC e as operações de backend para consolidação dos BICs e RFs operam dentro desta salvaguarda fundamental.23 Todavia, conforme vasto consenso da doutrina e sinalizações técnicas do Judiciário e da Autoridade Nacional de Proteção de Dados (ANPD), a ressalva do Art. 4º não confere ao Estado uma carta de imunidade sobre o vazamento indevido ou o tratamento imprudente dessas bases. A Polícia Federal e o Ministério da Justiça permanecem jungidos aos vetores da finalidade, minimização e segurança estrutural.23
A engenharia das 64 restrições combinatórias, exigindo um threshold elevado de acurácia antes da emissão via web do certificado (preferindo forçar o cidadão à agência física do que errar online) , atende perfeitamente ao princípio do Privacy by Design. A API mitiga o “scraping” indiscriminado, uma técnica onde mal-intencionados poderiam submeter milhares de CPFs de forma bruta para garimpar as fichas de cidadãos.
Neste ínterim legislativo, a jurisprudência do Superior Tribunal de Justiça, ao revisar os primeiros anos da vigência e aplicabilidade da LGPD 20, forjou precedentes essenciais para a calibração de riscos de vazamentos (sejam do portal Gov.br ou de corporações). O STJ consolidou (com amparo na Súmula 7) que o acesso ilícito ou vazamento de dados de natureza estritamente “comum” (como as matrizes do SINIC: nome, data de nascimento, filiação e CPF, sem acompanhamento de histórico) não autorizam a condenação imediata e presuntiva da entidade gestora em danos morais (in re ipsa).20 Indenizações sob a égide da LGPD demandam, invariavelmente, que o requerente produza prova cabal de que a disponibilização indesejada infligiu um dano concreto ou abalo relevante — servindo como barreira a uma enxurrada de demandas judiciais por simples bugs de interface.20
Entretanto, este manto protetor processual esvanece no exato instante em que o sistema cruza a fronteira e revela indevidamente a face subordinada da arquitetura (o Boletim Individual Criminal – BIC). Se falhas no ePol-SINIC ou sistemas análogos resultarem no acesso indevido por terceiros não autorizados a laudos processuais em segredo de justiça, histórico de regressão de regime ou condenações em tramitação (não transitadas em julgado), cessa-se o rótulo de “dano não comprovado”.20 A exposição irregular de atributos sancionatórios da cidadania é compreendida como violação autônoma à esfera moral e à intimidade 25, deflagrando responsabilidade sistêmica sem paralelo na administração pública.
9. Ação Corretiva na Base de Dados: Portaria MJSP nº 712/2024 e o Protocolo Nacional
Por mais sofisticadas que sejam a matemática das 64 combinações booleanas ou as regras de substituição de matrizes consonantais do algoritmo BuscaBR, toda heurística atua apenas mitigando as falhas semânticas legadas ao banco de dados pelo elemento humano de inserção (Garbage In, Garbage Out). A gênese esmagadora da colisão por homonímia, e dos falsos positivos no ePol-SINIC, deriva de décadas de práticas precárias nas bases da persecução penal, nas quais o Registro Federal (RF) de um cidadão comumente era preenchido por autoridades policiais em delegacias descentralizadas valendo-se apenas do que o preso verbalizava, sem confrontação biométrica. Indivíduos que ocultavam seu nome de batismo e forneciam os dados de primos ou vizinhos forjavam BICs criminais atrelados a RFs imaculados.
A neutralização dessas anomalias arquiteturais encontra-se em fase embrionária graças à intersecção entre tecnologia da informação, política de segurança e processo penal. Com fulcro em sanar essa disfuncionalidade civil e atender às demandas estruturais da criminologia contemporânea, foi editada a Portaria MJSP nº 712, de 24 de junho de 2024, promulgada pelo Ministro da Justiça e Segurança Pública, Ricardo Lewandowski.26
Esta portaria institui no Brasil o Protocolo Nacional de Reconhecimento de Pessoas em Procedimentos Criminais.26 O documento foi forjado com expressa convergência ao Tema Repetitivo 1.258 do STJ e projeta uma onda de impacto massivo e profundo sobre os meios de alimentação do ePol-SINIC, que deverá alcançar maturidade plena de adoção nos fluxos estaduais por volta do biênio 2025/2026.26
O Protocolo impõe rigorosas salvaguardas epistêmicas à fase inicial da cadeia de custódia (onde o BIC nasce). Restou expressamente vedado o uso de métodos sugestivos para reconhecimento, como o “show-up” (apresentar apenas um suspeito à vítima) ou a utilização discricionária de velhos catálogos físicos (álbuns de delegacia, não ancorados digitalmente).26 A normatização determina a utilização de alinhamentos criteriosos, envolvendo obrigatoriamente multiplicidade de indivíduos com fisionomias assemelhadas (o conceito forense internacional de fillers ou iscas) e, fundamentalmente, impõe a exigência do registro audiovisual compulsório de todas as etapas dos procedimentos identificatórios formais perante o sistema de justiça.26
O protocolo é de obediência impositiva e sumária aos órgãos federais (Polícia Federal e Força Nacional de Segurança Pública) e atua como uma recomendação balizadora robusta para todas as polícias estaduais (Civis e Militares). Para garantir a adesão estadual, o Governo Federal vinculou o recebimento das verbas de fomento do Fundo Nacional de Segurança Pública (FNSP) à absorção voluntária e técnica dessas diretrizes por parte das Secretarias Estaduais de Segurança Pública e entes da persecução judiciária.26 Adicionalmente, o programa previu subsídios aos agentes de ponta (como as cotas vinculadas ao Projeto Bolsa-Formação – PRONASCI) para acelerar a capacitação sistêmica na nova cultura de custódia.27
No escopo da arquitetura do ePol-SINIC, o advento dessa padronização representa a maior injeção de qualidade e higienização já projetada para a coluna vertebral da sua base de dados.28 À medida que novos BICs ingressam no ambiente relacional exclusivamente amparados por uma qualificação penal incontestável, ancorada em verificação audiovisual estruturada e controle cruzado, a carga de incerteza ontológica despenca vertiginosamente. Com isso, ao acessar a interface web no futuro para requerer uma Certidão de Antecedentes Criminais através das 64 matrizes de consulta, o cidadão de ficha limpa — notadamente o que opera sem chave de CPF informada e restrito aos limites das colisões e resoluções do motor fonético do BuscaBR — terá chances exponencialmente reduzidas de compartilhar o hash da matriz com Registros Federais corrompidos oriundos de identificações espúrias.28
10. Conclusão
O ecossistema que suporta o Sistema Nacional de Informações Criminais (ePol-SINIC) consubstancia a complexidade máxima do processamento de dados na administração pública federal. A modelagem do banco em instâncias hierárquicas — o Registro Federal (RF) unívoco subordinando os inumeráveis Boletins Individuais Criminais (BICs) — fornece a granularidade técnica necessária para suportar toda a máquina de persecução judiciária e policial.
A disponibilização massiva das certidões negativas à sociedade via portal de internet desvela a virtuosidade de um design algorítmico engenhoso: a formulação de uma matriz combinatória booleana estrita de 64 caminhos lógicos validados. Essa matriz demonstra um compromisso entre acessibilidade (permitindo buscas difusas a cidadãos desprovidos de extensa documentação civil) e segurança operacional, balizando o bloqueio sistêmico automatizado da emissão sempre que a clareza indexatória fonética da combinação inserida seja precária.
O emprego do algoritmo de raiz nacional BuscaBR na engrenagem central do processamento, em substituição ao modelo estrangeiro Soundex, reflete uma maturidade pericial inestimável na compressão e desambiguação dos fonemas peculiares, dialetos, mutações sintáticas e sotaques que estruturam o caos dos registros civis brasileiros contemporâneos.8
Ainda assim, a tecnologia transita em esferas onde os impactos resvalam incessantemente na tutela dos direitos fundamentais do indivíduo. A fricção gerada por retenções preventivas do sistema decorrente de homonímias ou colisões fonéticas gera interrupções severas ao cidadão que podem ocasionar ações diretas de regresso fundadas na teoria do risco e na responsabilização civil objetiva por parte do poder judiciário 5, enquanto corporações que manuseiam as informações do sistema alheias ao Tema 1 do TST enveredam em discriminação presumida em sede laboral.16 Tudo sob o invólucro exigente da LGPD, que impôs barreiras altíssimas à coleta e exposição de bases de histórico, protegidas excepcionalmente apenas para o exclusivo interesse da segurança pública.20
Em última instância, a consolidação deste framework tecnológico, agora amparada pelas rigorosas e modernas restrições impostas aos operadores da linha de frente pelo Protocolo Nacional de Reconhecimento de Pessoas (Portaria MJSP nº 712/2024) 26, traça um horizonte onde a extração de informações criminais pelas vias digitais do SINIC se distanciará progressivamente dos antigos fantasmas das confusões de identidade para se consolidar, invariavelmente, como um serviço público assertivo, resiliente à fraude e indissociável das prerrogativas da soberania cívica e judiciária.28
Referências citadas
- Emitir Certidão de Antecedentes Criminais – Governo Federal, acessado em março 31, 2026, https://www.gov.br/pt-br/servicos/emitir-certidao-de-antecedentes-criminais
- Certidão de Antecedentes Criminais – PCDF, acessado em março 31, 2026, https://www.pcdf.df.gov.br/servicos/antecedentes-criminais
- Indenização por danos morais: denúncia contra homônimo – Jus.com.br, acessado em março 31, 2026, https://jus.com.br/artigos/82690/indenizacao-por-danos-morais-denuncia-contra-homonimo
- STJ define em quais situações o dano moral pode ser presumido – PGE SE, acessado em março 31, 2026, https://pge.se.gov.br/stj-define-em-quais-situacoes-o-dano-moral-pode-ser-presumido/
- Certidão de Antecedentes Criminais — Catálogo de APIs governamentais, acessado em março 31, 2026, https://www.gov.br/conecta/catalogo/apis/antecedentes-criminais
- BUSCA FONÉTICA EM PORTUGUÊS DO BRASIL – T2Ti SISTEMAS, acessado em março 31, 2026, https://t2tisistemas.com/ead/pluginfile.php/2287/mod_forum/attachment/10718/fonetica.pdf?forcedownload=1
- BuscaBR Fonetica | PDF | Linguagem natural | Bancos de dados – Scribd, acessado em março 31, 2026, https://pt.scribd.com/doc/38615737/BuscaBR-Fonetica
- ALGORITMO SOUNDEX COMO ALTERNATIVA DE IDENTIFICAÇÃO DE PACIENTES EM FONTES DE DADOS HETEROGÊNEAS – Computação – UFES, acessado em março 31, 2026, https://computacao.alegre.ufes.br/sites/computacao.alegre.ufes.br/files/field/anexo/natalia_goncalves_machado.pdf
- Elaboração de uma Estratégia de Deduplicação de Dados Utilizando Técnicas de Blocagem em um Cadastro Hospitalar de Pacient – Lume UFRGS, acessado em março 31, 2026, https://lume.ufrgs.br/bitstream/handle/10183/26350/000757805.pdf?sequence=1
- Implementando Algoritmo BuscaBR – Linha de Código, acessado em março 31, 2026, http://www.linhadecodigo.com.br/artigo/2237/implementando-algoritmo-buscabr.aspx
- Learn in 10 minutes how to identify homonyms and paronyms in exam questions! – YouTube, acessado em março 31, 2026, https://www.youtube.com/watch?v=dTFWwLdFLM0
- Informativo de Jurisprudência do STJ destaca homônimo que responde a processo criminal, acessado em março 31, 2026, https://www.anoreg.org.br/site/informativo-de-jurisprudencia-do-stj-destaca-homonimo-que-responde-a-processo-criminal/
- Advogado criminal consegue mudança de nome por existência de homônimo acusado de crime – STJ, acessado em março 31, 2026, https://www.stj.jus.br/sites/portalp/Paginas/Comunicacao/Noticias/20062022-Advogado-criminal-consegue-mudanca-de-nome-por-existencia-de-homonimo-acusado-de-crime.aspx
- Tribunal Superior do Trabalho – TST, acessado em março 31, 2026, https://jurisprudencia-backend2.tst.jus.br/rest/documentos/2ca9d18b6c41d7dd56204be83c9cead1
- processo nº tst-irr-243000-58.2013.5.13.0023 c/j proc. nº tst-rr-184400-89.2013.5.13.0008, acessado em março 31, 2026, https://portal.trt3.jus.br/internet/jurisprudencia/incidentes-suscitados-irr-iac-arginc-tst/downloads/irr/AcordaoPublicado220917.pdf
- Nº 1: A exigência de apresentação de certidão de antecedentes criminais pelos candidatos ao emprego gera dano moral? | TRT6, acessado em março 31, 2026, https://www.trt6.jus.br/portal/jurisprudencia/temas-e-precedentes/14444
- REMI, v.07, 2025 ISSN 3085-9727 DANO MORAL NA EXIGÊNCIA DE CERTIDÃO DE ANTECEDENTE CRIMIN – Revista Multidisciplinar Integrada, acessado em março 31, 2026, https://revistas.unipacto.com.br/index.php/multidisciplinar/pt_BR/article/download/285/199/1477
- Moral damages and LGPD (Brazilian General Data Protection Law) — Legal Talk – YouTube, acessado em março 31, 2026, https://www.youtube.com/watch?v=qOfKsIdqFQk
- EXPOSIÇÃO DE MOTIVOS: Anteprojeto de Lei de Proteção de Dados para segurança pública e persecução penal O texto que ora – Poder360, acessado em março 31, 2026, https://static.poder360.com.br/2020/11/DADOS-Anteprojeto-comissao-protecao-dados-seguranca-persecucao-FINAL.pdf
- L13709 – Planalto, acessado em março 31, 2026, https://www.planalto.gov.br/ccivil_03/_ato2015-2018/2018/lei/l13709.htm
- Aplicabilidade da LGPD às atividades de segurança pública e persecução penal – JOTA, acessado em março 31, 2026, https://www.jota.info/opiniao-e-analise/artigos/aplicabilidade-da-lgpd-as-atividades-de-seguranca-publica-e-persecucao-penal
- Os precedentes do STJ em quatro anos de vigência da LGPD, acessado em março 31, 2026, https://www.stj.jus.br/sites/portalp/Paginas/Comunicacao/Noticias/2024/27102024-Os-precedentes-do-STJ-nos-primeiros-quatro-anos-de-vigencia-da-Lei-Geral-de-Protecao-de-Dados-Pessoais.aspx
- Ementário 09/2025 – Lei Geral de Proteção de Dados Pessoais — Tribunal de Justiça do Distrito Federal e dos Territórios – TJDFT, acessado em março 31, 2026, https://www.tjdft.jus.br/consultas/jurisprudencia/jurisprudencia-em-temas/ementario-eletronico-tematico/ementario-09-2025-lei-geral-de-protecao-de-dados-pessoais
- Portaria do MJSP institui protocolo nacional para padronizar o reconhecimento de pessoas em investigações criminais | MPPR, acessado em março 31, 2026, https://site.mppr.mp.br/criminal/Noticia/Portaria-do-MJSP-institui-protocolo-nacional-para-padronizar-o-reconhecimento-de
- PORTARIA MJSP Nº 712, DE 24 DE JUNHO DE 2024 – DOU – Imprensa Nacional, acessado em março 31, 2026, https://www.gov.br/mj/pt-br/acesso-a-informacao/acoes-e-programas/pronasci/bolsa-formacao/PORTARIAMJSPN712DE24DEJUNHODE2024DOUImprensaNacional.pdf
- Ministério da Justiça consolida o SINIC como base nacional de informações criminais, acessado em março 31, 2026, https://abrapol.org.br/ministerio-da-justica-consolida-o-sinic-como-base-nacional-de-informacoes-criminais/
- Novo Protocolo Nacional de Reconhecimento de Pessoas – Estratégia Carreira Jurídica, acessado em março 31, 2026, https://cj.estrategia.com/portal/protocolo-nacional-reconhecimento-pessoas-prova/
- Ministério estabelece normas para uso de informações criminais no país – Agência Brasil, acessado em março 31, 2026, https://agenciabrasil.ebc.com.br/geral/noticia/2026-01/ministerio-estabelece-normas-para-uso-de-informacoes-criminais-no-pais
- Portaria MJSP nº 712, de 24 de junho de 2024 – DSpace MJ, acessado em março 31, 2026, https://dspace.mj.gov.br/handle/1/13125?locale=pt_BR
