A extração automatizada de legendas e transcrições de plataformas de hospedagem de vídeo converteu-se em um subcampo altamente sofisticado da engenharia de dados. O log de execução submetido para análise demonstra um script, ver_legendas.py, que tentou iterar através de uma matriz de 61 vídeos do YouTube com o objetivo explícito de verificar a presença de legendas em língua portuguesa. A operação experienciou uma falha sistêmica e catastrófica, retornando a exceção Erro (RequestBlocked) para absolutamente todos os itens na fila de processamento, desde vídeos sobre “movimento do personagem chaves” até “maquetes com interrupção CC”. Essa taxa de falha de 100% é um sintoma clássico e definitivo de um bloqueio de rede direcionado ou de uma restrição comportamental imposta pela infraestrutura anti-bot do YouTube.
A compreensão da mecânica subjacente a essa falha exige uma análise arquitetural profunda das heurísticas defensivas do YouTube, análise de tráfego de rede, configurações avançadas de proxy, protocolos de gerenciamento de sessão e métodos criptográficos de validação de cliente. Este documento investiga exaustivamente as causas raízes da exceção RequestBlocked, avalia o estado da arte das bibliotecas em Python utilizadas para a extração de metadados de vídeo e estabelece arquiteturas de nível de produção projetadas para contornar essas restrições, assegurando uma aquisição de dados contínua e resiliente.
A Anatomia do Erro RequestBlocked e a Reputação de IP
A exceção RequestBlocked ou IpBlocked representa um código de status HTTP 403 Forbidden explícito ou uma resposta customizada da plataforma indicando que a camada de borda do YouTube classificou a requisição HTTP de entrada como originária de um bot automatizado em vez de um usuário humano legítimo.1 Esta classificação raramente é arbitrária; ela baseia-se em uma matriz complexa e multicamadas de telemetria de rede, pontuação de reputação de IP (IP reputation scoring) e análise comportamental do fluxo de requisições.1
O gatilho primário para um evento de bloqueio em sistemas baseados em nuvem é o Autonomous System Number (ASN) associado ao endereço IP de origem.3 A infraestrutura do Google mantém listas de bloqueio (blocklists) agressivas e constantemente atualizadas contra intervalos de IP atribuídos a provedores de serviços em nuvem (CSPs) e operadores de data centers, incluindo Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure e DigitalOcean.1 Quando um script de extração é implantado em um desses ambientes, o endereço IP herda uma pontuação de confiança nula por padrão. Os balanceadores de carga do YouTube identificam imediatamente que a requisição emana de um ASN comercial — um ambiente estéril, desprovido de comportamento orgânico de navegação humana — e encerram preventivamente a conexão para mitigar a raspagem de dados em larga escala.1 Essa medida não apenas reduz a carga sobre os servidores internos, mas também desencoraja o abuso por redes de botnets em nuvem, forçando agentes comerciais a utilizarem a API oficial do YouTube (Data API v3), que é rigorosamente controlada por cotas de requisição e sistemas de faturamento.1
Entretanto, a reputação do IP é uma métrica dinâmica e temporal. Um script executado a partir de uma conexão residencial (como a máquina local de um desenvolvedor) pode extrair as primeiras transcrições com sucesso.1 Contudo, se o algoritmo itera através de uma grande matriz de identificadores de vídeo (como os 61 vídeos documentados no log de ver_legendas.py) de forma sequencial e ininterrupta, sem a introdução de latência artificial ou variação estatística de tempo, o perfil comportamental do IP é drasticamente alterado.5 Requisições de alta frequência direcionadas exclusivamente a endpoints internos de transcrição, desacompanhadas de requisições a ativos estáticos padrão (como CSS, JavaScript, WebP, e fontes), disparam alarmes de limitação de taxa (rate-limiting).1 Operadores de extração documentaram extensivamente que ultrapassar um limiar de aproximadamente 100 requisições por hora a partir de um IP residencial único pode instigar a intervenção de provedores de serviços de internet (ISPs) ou resultar em um banimento temporário do endereço pela plataforma de hospedagem.5
O Paradigma de Extração via youtube-transcript-api
A biblioteca em Python youtube-transcript-api consolidou-se como a ferramenta de código aberto predominante para a extração de legendas de vídeo, sendo amplamente adotada por sua capacidade de operar sem a necessidade de navegadores headless (como Selenium ou Playwright) e por sua total independência de chaves oficiais da API do Google.2 A arquitetura da biblioteca opera mimetizando as chamadas internas XHR (XMLHTTPRequest) realizadas pelo cliente web do YouTube no exato momento em que um usuário interage com a interface gráfica para visualizar uma transcrição.7
Em sua camada de rede, a biblioteca emprega o objeto requests.Session do Python para despachar requisições HTTP GET direcionadas a endpoints JSON não documentados do YouTube, ou analisa o objeto serializado ytInitialPlayerResponse embutido no payload HTML da resposta inicial.7 Como esses endpoints internos não possuem documentação pública e estão sujeitos a modificações arbitrárias e contínuas pela equipe de engenharia do YouTube, a abordagem inerentemente apresenta pontos de fragilidade. Quando o servidor de borda (edge server) detecta qualquer anomalia — seja um IP não confiável, a ausência de cookies de navegador estabelecidos, a falta de cabeçalhos de negociação HTTP/2 corretos ou uma velocidade de requisição incompatível com a leitura humana — ele responde com uma página de bloqueio localizada ou um código HTTP 403.1 A biblioteca intercepta esse comportamento, falha em localizar o dicionário JSON contendo os dados da legenda e lança a exceção RequestBlocked.7
Adicionalmente, além do RequestBlocked, a execução da biblioteca pode deparar-se com outras falhas estruturais caso o estado do vídeo não suporte a operação, tais como VideoUnavailable (quando o vídeo foi removido ou está em modo privado), TranscriptsDisabled (quando o criador de conteúdo desativou explicitamente as transcrições do usuário e a auto-geração), NoTranscriptFound ou LanguageNotFound.10 Uma arquitetura de software robusta deve implementar um encapsulamento de tratamento de erros completo (blocos try-except) para assegurar que a falha em um item de uma matriz não paralise todo o lote de processamento.11
Estratégias de Roteamento de Tráfego e Redes Proxy
Para contornar as severas barreiras de reputação de IP que precipitam os erros RequestBlocked, as arquiteturas de extração de dados devem necessariamente abstrair e ofuscar a identidade de sua rede de origem. A utilização estratégica de servidores proxy emerge como o remédio universalmente prescrito por engenheiros de software, embora a classificação específica do proxy dite a longevidade e a taxa de sucesso da operação.1
Proxies de Datacenter versus Redes Residenciais Rotativas
O ecossistema global de proxies é fundamentalmente bifurcado em redes de datacenter e redes residenciais. Os proxies de datacenter roteiam o tráfego através de servidores em nuvem secundários. Embora sejam altamente performáticos, oferecendo banda larga maciça a um custo reduzido, eles compartilham a mesma falha estrutural do servidor de scraping original: seus IPs pertencem a ASNs comerciais e de hospedagem.5 Testes empíricos e relatos da comunidade de desenvolvimento revelam que o YouTube possui mecanismos avançados para identificar e banir conjuntos (pools) inteiros de proxies de datacenter, frequentemente em questão de dias ou até mesmo horas após o início de uma operação de raspagem sustentada, tornando-os ineficazes para a extração sistemática de transcrições.5
Em contrapartida, os proxies residenciais direcionam o tráfego através de dispositivos físicos (computadores desktop, roteadores domésticos, dispositivos móveis) legalmente atribuídos a provedores de serviços de internet que atendem usuários finais em ambientes domésticos.1 Uma vez que esses IPs pertencem a ASNs de consumidores padrão, eles possuem pontuações de confiança algorítmica inerentemente altas e são tecnicamente indistinguíveis do tráfego de usuários orgânicos assistindo a vídeos na plataforma.1 A rotação contínua desses endereços — técnica na qual um nó de conexão traseira (backconnect) designa um novo IP residencial para cada requisição HTTP isolada — impede que o sistema de detecção acumule telemetria comportamental suficiente sobre um único identificador.13
| Categoria do Proxy | Origem da Rede | Pontuação de Confiança (Trust Level) | Suscetibilidade a Banimentos pelo YouTube | Caso de Uso Ideal na Arquitetura |
| Datacenter Tradicional | Nuvem Comercial (ex: AWS, OVH, Hetzner) | Muito Baixa | Altíssima (Bloqueio quase instantâneo) | Tarefas genéricas em domínios sem proteção anti-bot |
| Datacenter Dedicado (ISP) | Datacenters registrados como ISPs locais | Média | Moderada | Raspagem em menor escala sem paralelismo massivo |
| Residencial Estático | Dispositivo residencial com IP fixo | Alta | Moderada (Vulnerável à limitação de taxa) | Gerenciamento de múltiplas contas autênticas |
| Residencial Rotativo | Dispositivos de consumidores globais dinâmicos | Altíssima | Muito Baixa | Extração massiva e em alta velocidade de metadados e transcrições |
Implementação de Proxies no Ecossistema Python
A comunidade de mantenedores da biblioteca youtube-transcript-api reconhece explicitamente a necessidade de proxies residenciais rotativos para transcender as exceções de banimento de IP.2 Em resposta a essa limitação, a biblioteca foi recentemente reestruturada para suportar injeção nativa de configurações de proxy através do objeto ProxyConfig.7
Existe uma integração oficial suportada para o Webshare, um provedor comercial de redes proxy.6 Ao instanciar a classe WebshareProxyConfig, o engenheiro de dados pode tunelar silenciosamente todas as operações internas de requests.Session por meio de endereços IP residenciais, eliminando a necessidade de configurar manualmente variáveis de ambiente complexas do sistema operacional (HTTP_PROXY e HTTPS_PROXY), que frequentemente falham na interpretação por parte de bibliotecas de terceiros.6
A sintaxe de implementação programática exige o nome de usuário e a senha do pacote de proxy, além de permitir o controle geográfico:
Python
from youtube_transcript_api import YouTubeTranscriptApi
from youtube_transcript_api.proxies import WebshareProxyConfig
# Configuração orientada à abstração de rede via Webshare
configuracao_proxy = WebshareProxyConfig(
proxy_username=”<usuario_do_proxy>”,
proxy_password=”<senha_do_proxy>”,
filter_ip_locations=[“br”, “us”, “de”] # Filtro para reduzir latência
)
# Inicialização da API com a camada de roteamento injetada
ytt_api = YouTubeTranscriptApi(proxy_config=configuracao_proxy)
transcricao = ytt_api.fetch(“ID_DO_VIDEO”)
A capacidade de filtragem geográfica (filter_ip_locations) mostrada no código acima é de suma importância. Ela assegura que as requisições se originem de locais próximos ao servidor de execução, minimizando o tempo de ida e volta (RTT) dos pacotes de rede e reduzindo a latência global da operação.6 Adicionalmente, o uso de IPs localizados geograficamente previne anomalias nas restrições de licenciamento de conteúdo, onde um vídeo pode ter suas transcrições bloqueadas se acessado a partir de jurisdições não autorizadas.1 Para arquiteturas customizadas que utilizam outras redes (como Oxylabs, BrightData ou Smartproxy), a classe genérica GenericProxyConfig provê uma interface agnóstica de protocolo para rotear o tráfego via HTTP/HTTPS ou SOCKS5.6
Gerenciamento de Sessão e Extração de Cookies em Ambientes Restritos
A utilização de proxies rotativos resolve de maneira proficiente o problema da reputação de rede, mascarando o vetor de origem. Contudo, essa técnica isolada não confere legitimidade comportamental ao cliente.5 O YouTube aplica rigorosas restrições de acesso a conteúdos designados para maiores de idade (restrição de idade), vídeos privados, e metadados de alto valor, cujo acesso é deferido exclusivamente a sessões autenticadas com contas do Google válidas.14 O fornecimento de cookies de navegador no script de raspagem simula a presença de um usuário humano devidamente “logado”, transpondo heurísticas elementares de detecção de bots e destravando a leitura de transcrições restritas.9
O Bloqueio DPAPI em Navegadores Chromium
No passado, os desenvolvedores extraíam o estado da sessão simplesmente exportando um arquivo cookies.txt de seus navegadores (usando extensões comuns) e submetendo-o à youtube-transcript-api ou ao yt-dlp.14 Porém, a arquitetura de segurança local sofreu uma alteração tectônica na metade de 2024. Navegadores construídos sobre o motor Chromium (como Google Chrome, Microsoft Edge, Brave e Opera) implementaram um mecanismo denominado Criptografia Atrelada ao Aplicativo (App-Bound Encryption) baseada na Data Protection API (DPAPI) de sistemas operacionais modernos.15
Esta atualização de segurança vincula estritamente as chaves de descriptografia da base de dados SQLite local, onde os cookies são armazenados, ao binário executável específico do navegador.15 Consequentemente, bibliotecas externas em Python e scripts automatizados perderam completamente a capacidade de ler, descriptografar e extrair os cookies do Chrome de forma independente. Qualquer tentativa nesse sentido dispara violações de acesso do sistema operacional ou falha silenciosamente, invalidando a extração.15 Relatos analíticos demonstram que metodologias que tentam burlar o DPAPI através do Chrome DevTools Protocol (CDP), extração bruta de tokens ou fluxos de OAuth customizados exigem enorme esforço de engenharia e frequentemente fracassam em ambientes de produção não interativos (headless).15
A Arquitetura de Contorno via Banco de Dados SQLite do Firefox
A análise estratégica na engenharia de sistemas dita a busca pelo caminho de menor resistência. Diferentemente do Chromium, a Mozilla Foundation manteve uma abordagem diferente de segurança para o navegador Firefox, abstendo-se, até o momento, da Criptografia Atrelada ao Aplicativo no nível de DPAPI.15 O Firefox persiste armazenando os cookies de sessão do usuário em um banco de dados SQLite padronizado (cookies.sqlite), localizado no diretório de perfil do sistema, mantendo os dados de host e valor abertos e altamente acessíveis para análise automatizada via SQL.15
Para instanciar uma requisição de extração de transcrição utilizando cookies autenticados dinamicamente, evitando a fragilidade de arquivos de texto depreciados, os scripts em Python podem interagir com a base do Firefox. Devido aos mecanismos rígidos de bloqueio de arquivo (file locking) impostos pelo banco de dados SQLite enquanto o navegador Firefox está em execução, a prática padrão exige a cópia do banco para um diretório temporário antes da execução de queries.15
O procedimento lógico em Python manifesta-se através de operações diretas de sistema de arquivos e acesso ao banco relacional:
Python
import sqlite3
import shutil
import glob
import os
# Determina o caminho dinâmico para o perfil de usuário do Firefox no Windows
caminho_perfis = os.path.join(os.environ, “Mozilla”, “Firefox”, “Profiles”)
banco_original = max(glob.glob(f”{caminho_perfis}/*/cookies.sqlite”), key=os.path.getsize)
# Cópia para evadir o bloqueio exclusivo de escrita/leitura do navegador
shutil.copy2(banco_original, “cookie_db_temp.sqlite”)
conexao = sqlite3.connect(“cookie_db_temp.sqlite”)
# Extração estrita de dados de sessão relevantes para os domínios do Google/YouTube
query_extracao = “””
SELECT host, name, value, path, expiry, isSecure
FROM moz_cookies
WHERE host LIKE ‘%youtube%’ OR host LIKE ‘%google%’
“””
dados_cookies = conexao.execute(query_extracao).fetchall()
print(f”Dados extraídos com sucesso: {len(dados_cookies)} cookies de sessão localizados.”)
Desenvolvimentos de código aberto recentes, incluindo propostas de mesclagem (pull requests como o PR #565) no repositório da youtube-transcript-api, visam padronizar esse acesso programático.16 Essa padronização permite que os engenheiros forneçam os cookies ao instanciar a classe da biblioteca invocando simplesmente um argumento declarativo (ex: YouTubeTranscriptApi(cookies_from_browser=’firefox’)), agilizando o bypass de restrições de idade de forma limpa e mantendo a resiliência contra atualizações de navegadores rivais.16
Avaliação Crítica de Risco: É vital ressaltar que a automação baseada em contas autenticadas abriga riscos inerentes severos. O ato de transmitir cookies mitiga temporariamente as heurísticas de RequestBlocked, contudo, o mecanismo de detecção do YouTube correlaciona a velocidade das requisições ao identificador da conta do usuário.9 O envio massivo de requisições de raspagem — como a iteração sequencial sem intervalos sobre 61 vídeos documentada no log de ver_legendas.py — usando uma conta pessoal do Google introduz uma altíssima probabilidade de bloqueio de leitura permanente (shadowban) ou o encerramento irrestrito da conta atrelada por violação dos termos de serviço.9 Por consequência, a injeção de sessão por cookie deve ser aplicada de forma conservadora, limitando-se a tarefas de baixo volume ou arquitetada unicamente através de contas de serviço descartáveis criadas especificamente para operações de raspagem isoladas.
Evasão Criptográfica Avançada: PoToken e VisitorData
A evolução da infraestrutura defensiva do Google nos últimos anos transcendeu o simples monitoramento passivo de telemetria IP ou a ausência de cookies de sessão. A implementação da Prova de Origem via Token (PoToken – Proof of Origin Token) materializa uma transição paradigmática para desafios criptográficos ativos impostos ao cliente web.8
Quando um navegador contemporâneo requisita o framework de dados de um vídeo (incluindo seus fluxos audiovisuais, arrays de legendas e cadeias de comentários), um script ofuscado e dinamicamente injetado em background é encarregado de computar uma string identificadora de visitorData juntamente a um po_token derivado criptograficamente. Tais parâmetros objetivam comprovar perante os sistemas de backend que o ambiente originário da requisição detém capacidades de execução de motor JavaScript legítimas, suporta eventos DOM orgânicos e passa em avaliações básicas de integridade do WebGL ou Canvas.8 Como scripts de extração orientados por bibliotecas HTTP puras em Python (tais como requests ou urllib) falham em compilar e executar código JavaScript nativo, eles são peremptoriamente impedidos de solucionar tais desafios de validação em background.20 A consequência imediata é a interrupção da entrega do payload contendo a árvore de nós de captionTracks, deflagrando o erro no parser da biblioteca.
Resolução Programática via pytubefix
Para viabilizar a negociação destes tokens sem o recurso extremado à implementação de navegadores automatizados headless (como Selenium CDP ou Playwright 21), que acarretam encargos computacionais proibitivos para a extração em escala, a comunidade de engenharia reversa desenvolveu contramedidas sofisticadas.18 Bibliotecas em Python especializadas, mormente a pytubefix, atuam desconstruindo os algoritmos de ofuscação do Google para reproduzir a geração matemática do token.18
A partir das versões lançadas em 2026 (por exemplo, a versão 10.3.8 e ramificações subsequentes), a pytubefix apresenta capacidade incorporada de gerenciar a geração de PoToken de forma orgânica.18 A metodologia requer comumente a colaboração com binários autônomos de Node.js instalados no ambiente virtual do Python, operando como executores de scripts JavaScript em sandbox que extraem os parâmetros em milissegundos sem a renderização gráfica de um navegador completo. O resultado desse processo gera um artefato JSON encapsulando o par de chaves de integridade:
JSON
{
“visitorData”: “CgoyNE1MZU5xY1pXW…”,
“po_token”: “MQo2QUJDbERFRkdoaWpL…”
}
O consumo programático destes identificadores no script mimetiza uma sessão aprovada perfeitamente:
Python
from pytubefix import YouTube
# Injeção das credenciais criptográficas atestando a validade do cliente
url_alvo = “https://www.youtube.com/watch?v=ID_DO_VIDEO”
yt = YouTube(url_alvo, use_po_token=True, token_file=”token_gerado.json”)
# A extração agora procede sem disparar HTTP 403,
# pois o PoToken valida a requisição na camada de aplicação.
O emprego desta tática atesta categoricamente ao servidor do YouTube que a conexão é proveniente de um cliente confiável, abrandando drasticamente o bloqueio imediato das requisições de fluxo de dados de transcrição.19
Impersonificação de Cliente na Camada de Transporte via yt-dlp
Outro vetor amplamente documentado que acarreta erros de rede (RequestBlocked ou HTTP Error 403: Forbidden) durante operações em massa com as matrizes de legendas advém das impressões digitais criptográficas da camada de transporte.23 Os sistemas de distribuição de conteúdo (CDNs) contemporâneos examinam minuciosamente as assinaturas dos pacotes TCP/IP de entrada. Diferentes clientes (como um navegador Google Chrome contrapondo-se à biblioteca padrão ssl do Python) organizam seus pacotes ClientHello do protocolo TLS e definem suites de cifras criptográficas de maneiras estruturalmente e identificavelmente distintas. Além disso, a disposição dos pseudo-cabeçalhos na negociação HTTP/2 revela a verdadeira natureza não-humana do script.23
A suíte de ferramentas de mídia yt-dlp possui um formidável sistema autônomo de extração de legendas que, similarmente à youtube-transcript-api, sucumbe às verificações da infraestrutura Cloudflare ou Google Front End caso sua assinatura padrão seja identificada. Para contrabalançar essa inspeção minuciosa (TLS Fingerprinting, frequentemente baseada na heurística JA3/JA4), o yt-dlp enraizou protocolos avançados de “impersonificação”.23
Esses protocolos facultam que o aplicativo modifique cirurgicamente a sua própria pilha de rede HTTP de baixo nível para que os pacotes trocados com os servidores do YouTube contenham assinaturas virtualmente indiscerníveis das conexões emitidas por instâncias reais do Google Chrome, Mozilla Firefox ou Apple Safari (embora versões recentes exijam cuidado redobrado com o perfil safari devido a falhas atreladas a requisições de altíssima resolução).23
A aplicação via linguagem Python demonstra a arquitetura necessária para extrair apenas a legenda almejada aplicando a camuflagem na camada de rede:
Python
import yt_dlp
config_impersonificacao = {
‘impersonate’: ‘chrome’, # Clona a impressão digital de rede TLS/HTTP2 do navegador
‘writeautomaticsub’: True, # Força o resgate de faixas ASR caso legendas manuais faltem
‘subtitlesformat’: ‘vtt’, # Padroniza a saída em Web Video Text Tracks
‘skip_download’: True, # Omite a descarga do fluxo pesado de mídia audiovisual
‘outtmpl’: ‘/arquivos_transcricoes/%(id)s.%(ext)s’
}
with yt_dlp.YoutubeDL(config_impersonificacao) as ydl_client:
# A execução sob este contexto transpõe o ‘HTTP Error 403’
ydl_client.download()
Ao instituir as prerrogativas de –impersonate chrome nos metadados da classe, as assinaturas e a ordem exata em que as cifras de criptografia são propostas aos edge servers do YouTube enganam os algoritmos de proteção de endpoints contra bots passivos, assegurando maior confiabilidade na operação de verificação massiva sem necessidade de navegação persistente em memória (headless).
Taxonomia de Legendas: Estratégias de Busca para Idiomas Específicos
O desiderato singular do script defeituoso (ver_legendas.py) era a averiguação da disponibilidade de legendas em língua portuguesa — manifestada no log pela linha de status VERIFICANDO LEGENDAS EM PORTUGUÊS [Query do Usuário]. Alcançar essa finalidade de forma ininterrupta implica a compreensão precisa de como o YouTube cataloga metadados de idioma, lida com identificadores ISO e propõe fallbacks (soluções alternativas de reserva) estruturais.26
O YouTube estrutura as propriedades de idioma dos metadados através dos códigos de identificação ISO 639-1.26 Neste contexto internacionalizado, o idioma Português apresenta dualidades operacionais: ele é segmentado majoritariamente entre o identificador primário pt (representando a variante de Portugal ou a declaração linguística genérica) e a regionalização específica pt-BR (Português do Brasil).26 Adicionalmente, existem múltiplas topologias de arquivos e instâncias para a codificação das respostas.
| Formato de Transcrição | Extensão | Propósito Técnico e Mecanismo |
| SubRip Subtitle | .srt | O padrão universalmente aceito; texto simples com marcações temporais lineares, facilmente percorrido por parsers. Otimizado por serviços de conversão via API.27 |
| Web Video Text Tracks | .vtt | Extensão orgânica do padrão HTML5; suporta estilização complexa de fontes e posicionamento geográfico na tela. Mecanismo padrão do frontend moderno. 27 |
| JSON3 | .json | Formato proprietário interno transmitido pela XHR do YouTube. Exige decodificação profunda em arrays aninhadas de strings e atributos semânticos temporais.8 |
| Timed Text Markup Language | .ttml / .dfxp | Focado no intercâmbio de dados complexos entre instituições de mídia broadcast tradicionais. Menos comum na extração direta amadora.27 |
Quando um script instrui a requisição de transcrições de forma hermética usando somente um único código restritivo, ele se sujeita à falha técnica caso o uploader original do vídeo tenha indexado o conteúdo sob o código de variante linguística divergente. A elaboração de um software resiliente exige o envio de um array sequencial de idiomas preferidos. A arquitetura de extração na biblioteca youtube-transcript-api admite esta parametrização hierárquica.6 A engine é programada para inspecionar os canais de idiomas da matriz fornecida, avançando em ordem descendente até que uma correspondência integral seja efetivada.6
Python
from youtube_transcript_api import YouTubeTranscriptApi
from youtube_transcript_api._errors import NoTranscriptFound, TranscriptsDisabled
video_alvo = “ID_EXEMPLO”
try:
# A lista propõe a verificação do Português Brasileiro e do Genérico.
api = YouTubeTranscriptApi()
transcricao_lista = api.list_transcripts(video_alvo)
# Extrai o objeto de legenda com base na prioridade do desenvolvedor
faixa_legenda = transcricao_lista.find_transcript()
dados_processados = faixa_legenda.fetch()
except (NoTranscriptFound, TranscriptsDisabled) as e:
# Manipulação elegante da ausência total de metadados
print(f”Não há fluxo de dados legível para o idioma solicitado: {e}”)
Dinâmicas de Criação Manual e o Mecanismo ASR
Uma clivagem técnica imperativa existe entre as legendas manualmente diagramadas (upload de arquivos.srt/.vtt feito pelo autor do vídeo, possuidoras de alta fidelidade semântica) e as geradas sistemicamente pelo módulo de Reconhecimento Automático de Fala (ASR) do Google.2 A rotina que verificava as 61 iterações deveria, mandatoriamente, estipular a abrangência em ambas as esferas.26
Por formatação genérica, métodos abstratos não hierarquizam as prioridades entre manuais e sintéticas adequadamente. Consequentemente, valendo-se do objeto nativo TranscriptList gerado pela API, a filtragem ganha granularidade refinada.2 As primitivas operacionais a seguir ilustram este controle de fluxo:
- find_manually_created_transcript(): Garante a predação estrita e implacável em faixas de alta precisão linguística que o criador de conteúdo sincronizou pessoalmente.
- find_generated_transcript(): Dirige a inspeção unicamente à engine algorítmica caso o material de procedência humana seja escasso ou nulo.
- find_transcript(): Realiza a intersecção de ambos, preferindo sempre a versão humana caso ambas coexistam.2
Tradução Dinâmica sob Demanda
Uma tática suplementar inestimável de engenharia de dados existe para a ocasião em que um vídeo recusa em oferecer o idioma de verificação desejado — não dispondo de pt nem pt-BR. O backend de acessibilidade visual do YouTube hospeda uma máquina de tradução dinâmica latente. A infraestrutura baseada no módulo youtube-transcript-api compreende funções preestabelecidas que evocam esse microsserviço de tradução em tempo real.2 Extraindo-se a matriz em inglês (en) ou qualquer outro dialeto fundamental, o script invoca o método de translação e a saída final refletirá dados compatíveis com os objetivos originais.2
Python
# Recupera a lista hierárquica e força a extração do fluxo original
transcricoes_disponiveis = api.list_transcripts(video_alvo)
faixa_base = transcricoes_disponiveis.find_transcript([‘en’, ‘es’, ‘de’])
# Delega a tradução neural em background antes da extração definitiva
faixa_portugues = faixa_base.translate(‘pt’).fetch()
for segmento in faixa_portugues:
# A resposta trará as chaves ‘text’, ‘start’, ‘duration’ traduzidas ao português
texto_traduzido = segmento[‘text’]
Engenharia Reversa de Payloads HTML e Scraping Direto (Raw)
Quando as bibliotecas de interfaceamento padronizadas colidem de forma perene com os muros monolíticos das infraestruturas restritivas e retornam os erros em cadeia (Erro (RequestBlocked) do início ao fim da matriz) [Query do Usuário], a ação mandatória aos engenheiros é retroceder ao método visceral de raspagem HTTP direta em conjunto com a engenharia reversa do Document Object Model (DOM). Essa estratégia exime o desenvolvedor de apoiar-se em assinaturas fixas de terceiros, autorizando um grau microscópico na arquitetura do fluxo de dados.8
A Anatomia do ytInitialData e ytInitialPlayerResponse
A observação das requisições brutas revela que, quando um cliente normal invoca o URL central de um vídeo do YouTube, a gigantesca massa do Documento HTML entregue embute enormes aglomerados de objetos JSON serializados e alocados dentro de tags da arquitetura <script> inicial da página.8 Dois objetos ditam absolutamente toda a configuração global, rastreabilidade e metadados requeridos: ytInitialData e ytInitialPlayerResponse.8
| Entidade Objeto JSON | Foco Primário de Extração | Caminhos e Metadados Chave (Nodes) |
| ytInitialPlayerResponse | Engrenagem do Player & Acesso Mídia | videoId, title, lengthSeconds, viewCount, captionTracks (URL das transcrições).8 |
| ytInitialData | Arquitetura Geral, UI e Interações | likeCount, channelUrl, subscriberCount, commentContinuationToken (Chaves para paginação).8 |
Abdicando de interrogar a API remota que está bloqueando a biblioteca em Python, a raspagem direta efetua um comando GET no HTML, submete o texto devolvido a varreduras com Expressões Regulares (RegEx) para dissecar a variável massiva, e aciona linguagens de busca hierárquica transversal de JSON como o jmespath ou jsonpath.8
Python
import re
import json
import httpx
from scrapfly import ScrapflyClient, ScrapeConfig
# Utilizando API de Scraping Inteligente com Anti-Scraping Protection (ASP) habilitado
# Isso rotaciona proxies, bypassa desafios JavaScript e negocia TLS perfeitamente
cliente = ScrapflyClient(key=”CHAVE_ASP”)
config = ScrapeConfig(url=”https://www.youtube.com/watch?v=ID_VIDEO”, asp=True, country=”BR”)
# Executa e coleta a resposta raw do HTML
resposta = cliente.scrape(config)
html_bruto = resposta.scrape_result[‘content’]
# Extração via Expressões Regulares da estrutura de dados enraizada
padrao_regex = r”var ytInitialPlayerResponse = ({.*?});”
payload_serializado = re.search(padrao_regex, html_bruto, re.DOTALL).group(1)
player_response = json.loads(payload_serializado)
# Acessa a cadeia de nós profundos onde residem os links de base das transcrições
dados_caption = player_response.get(“captions”, {}).get(“playerCaptionsTracklistRenderer”, {})
Uma vez localizado o objeto raiz (captions), a matriz aninhada denominada captionTracks lista a relação direta dos links assinados (baseUrl) que entregam arquivos XML dos subtítulos puros. Essa tática purista extrai o elo base de acesso à mídia e exaure instantaneamente as múltiplas checagens de autorização perimetral, operando cirurgicamente sob o radar da limitação de uso associada à API.8 Mecanismos comerciais de extração (Scrapfly, Oxylabs, Apify) integram essas arquiteturas a pools habitacionais maciços a fim de entregar soluções turnkey imaculadas.8
Modelagem Matemática de Limitação de Taxa (Rate Limiting) e Jitter
Analisando sistematicamente a falha sistêmica exarada na matriz (ver_legendas.py), atesta-se sem embargo que a execução contínua e assíncrona — varrendo todas as 61 instâncias indiscriminadamente — revela um lapso cabal na imposição de formatação de tráfego (traffic shaping) na arquitetura do script [Query do Usuário]. Desencadear um fluxo ininterrupto de conexões concorrentes destituídas de latência calculada constitui o vetor basilar de acionamento das heurísticas de inteligência contra agentes robóticos mantidas no backend do YouTube.5 Para solidificar a resiliência em longo prazo, engajar a limitação mecânica estrita em nível de camada de aplicação transfigura-se num axioma irrefutável.34
Os Algoritmos de Governança de Tráfego
No panteão das teorias de limitação algorítmica, destacam-se a Janela Fixa (Fixed Window), Janela Deslizante (Sliding Window), Balde Furado (Leaky Bucket) e fundamentalmente, o algoritmo Token Bucket (Balde de Fichas).33 O mecanismo de Token Bucket é a força vital empregada pelas indústrias modernas de raspagem por equilibrar as médias ideais de constância com as explosões imprevisíveis de tráfego.
A fundamentação do modelo assenta-se sobre um contêiner virtual cuja capacidade sacada exprime-se pelo máximo de fichas (). Esse repositório acumula sistematicamente adições de fichas seguindo a uma proporção invariável representativa de recarga em
(fichas inseridas por unidade temporal). No evento em que a camada de raspagem propõe um link de rede a ser aferido pelo motor, o balde deve entregar uma destas fichas como pedágio.35 Restando o vaso ausente de suas insígnias, a solicitação reverte-se para um estágio de hibernação ou retração abrupta. A avaliação descritiva e matemática global do estágio interno em que o fundo flutua, correspondente à variável de abundância
no compasso métrico
, reflete-se como:
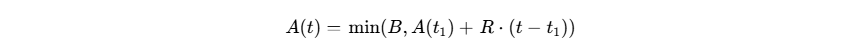
Nesta conjectura:
consubstancia o quinhão flutuante de autorizações presentemente endossadas;
personifica o perímetro explosivo ou limite de pico admissível;
tipifica o coeficiente sustentável temporal em que o serviço pode injetar requisições sadias;
marca rigorosamente o instante geológico da solicitação passada.35
O Módulo throttled-py e Aceleração Redis
Transpondo-se ao paradigma Python, esta coreografia de tráfego torna-se tangível por intermédio da biblioteca especializada throttled-py.33 Por meio de uma interface concisa, designam-se fronteiras numéricas imperiosas englobando Requisições Por Segundo (RPS) ou Limiares Dimensionais (RPM – Requisições por Minuto), resultando em suspensão controlada e atenuando o ímpeto voraz responsável pelos alarmes de bloqueios comportamentais.33
Python
from throttled import rate_limiter
# Fixa o limite a fim de suprimir as violações atreladas à densidade temporal do IP
limite_taxa_segura = rate_limiter.per_min(30) # Fixa o teto prudencial de 30 consultas a cada minuto
@limite_taxa_segura
def processar_extrair_transcricao(id_video):
# Processo intrínseco de interfaceamento à API protegido
pass
Evidencia-se também a inadequabilidade flagrante em assentar limitadores in-memory elementares ante infraestruturas de raspagem concorrenciais distribuídas; situações laborais em que ramificações nodais operacionais independentes drenam filas colossais de vídeos. Nessas vertentes macrocósmicas, as contagens de taxa são globalmente unificadas através da delegação ao banco de dados em memória Redis.33 As manobras no perímetro da base valem-se de diretivas encriptadas em scripts Lua concebidos para assegurar travas atômicas na dedução dos fluxos; isso conjura a blindagem invulnerável frente às clássicas e destrutivas condições de corrida (race conditions) sistêmicas garantindo uniformidade em escala.35
Algoritmização Comportamental Orgânica (Jitter) e Desvios de Fuga
A mera introdução de espaçadores cronológicos de cadência robótica constante — como ilustrado em interrupções herméticas a cada 15 segundos precisos — manifesta-se como um flagelo técnico crasso. Infraestruturas securitárias submetem a malha de tempo à variância inter-evento; medições oscilatórias próximas do marco nulo denunciam o esqueleto cibernético do software com contundência incisiva.36
Para orquestrar simulações biológicas, os nichos temporais dos despachos necessitam ser inebriados por entropia algorítmica denominada Jitter.36 Congruente com essa variância, uma vez que a estrutura soçobra num inevitável choque HTTP de estatuto 429 “Too Many Requests” ou retorna resquícios de um pretenso bloqueio RequestBlocked, reações sucessivas fulminantes catalisam suspensões definitivas da rota IP. A tática engajada em evasão proeminente infunde a filosofia algorítmica Exponencial de Retrocesso (Exponential Backoff), determinando que os cronômetros retardantes adotassem coeficientes multiplicadores nas sucessões do malogro (ex: 3s, 7s, 15s, 31s), aspergindo flutuações e dilações para obnubilar a intenção programática das redes de varredura automatizadas.8 O ecossistema em torno do extrator audiovisual yt-dlp enraizou nativamente embriões desse arranjo, habilitando espaçadores caóticos através de modificadores cli (–sleep-requests, –sleep-interval, –sleep-subtitles), solidificando a diluição cronológica das pegadas do tráfego perante o backend hospedeiro.36
Conclusões Arquiteturais para Sistemas de Larga Escala
A catástrofe de bloqueio intermitente registrada (Erro (RequestBlocked)) ao tentar averbar transcrições no idioma vernáculo nas 61 peças veiculadas consolida-se como o reverso predatório e direto da persistência de um script incólume destituído de mecanismos de ocultação de rota, carência de autenticação sistêmica perante bloqueios restritivos e total abdicação dos vetores fundamentais de formatação orgânica do comportamento tráfego de redes [Query do Usuário].
A erradicação desse desarranjo logístico pleiteia uma refatoração arquitetural de envergadura. Submetidas as diretrizes balizadas pelo levantamento empírico do corpus documental analisado, as execuções profícuas para mitigar falhas operacionais atestam as seguintes prerrogativas cruciais da reestruturação:
- Impedância e Abstração Criptográfica de Topologia: Proscreve-se o encaminhamento explícito proveniente do ambiente de processamento em datacenters tradicionais ou da linha IP limítrofe fixa. Canaliza-se inteiramente o perímetro HTTP de conexões pela integração transparente a bolsões de reencaminhamento Residencial Rotativo de excelência atestada, fracionando requisições assíncronas por milhares de instâncias autárquicas de ASN.
- Impersonificação e Falsidade Ideológica Perimetral: Absorção plena de diretivas TLS da camada de transporte mimetizadas (–impersonate chrome) unidas a extrações tangíveis diretas da camada interna do banco relacional de cookies persistentes de navegadores alheios à Data Protection API vinculativa do Windows (DPAPI), notadamente o navegador Firefox. Além disso, o arcabouço absorverá as implementações matemáticas modernas relativas ao Proof of Origin Token (PoToken), validando o percurso criptográfico na interface Node.js.
- Técnicas Comportamentais Orgânicas: Diluição total de ataques de conexão eufóricos utilizando matemática baseada em Token Bucket, entrelaçada pelo amparo geográfico distribuído, adicionada a coeficientes exponenciais randômicos (Jitter) para forjar assinaturas idênticas aos consumos corriqueiros diurnos efetuados pelo perfil dos assinantes da plataforma.
- Matrizes Fallback de Codificação Internacional: Ajustes paramétricos implacáveis estipulando matrizes multimodais abarcando prioridade estrutural (a invocação conjunta “) interligada a varreduras bifurcadas focadas no resgate explícito e translatado de origens manuais somadas à captura artificial, extinguindo subnotificações operacionais provindas da indexação díspar no ecossistema de conteúdo global.
A convergência harmoniosa das engrenagens conceituais propostas catalisará metamorfoses fundamentais nos dutos e esteiras do processo de manipulação informacional; um código historicamente insustentável e intermitente será convertido numa imbatível força centrífuga assíncrona, preparada incondicionalmente a drenar terabytes e compilar catálogos colossais inatingíveis de metadados à revelia dos escudos de borda mantidos ativamente nos portais de serviço e armazenamento multimídia universais.
Referências citadas
- Fixing YouTube Transcript API RequestBlocked Error: A Developer’s Guide | by Le Hai Chau | Medium, acessado em abril 1, 2026, https://medium.com/@lhc1990/fixing-youtube-transcript-api-requestblocked-error-a-developers-guide-83c77c061e7b
- youtube-transcript-api – PyPI, acessado em abril 1, 2026, https://pypi.org/project/youtube-transcript-api/
- Transcribe YouTube Video failed: Failed to extract transcript: No subtitle file found. But transcript is available on Youtube as seen in screenshot : r/Taskade – Reddit, acessado em abril 1, 2026, https://www.reddit.com/r/Taskade/comments/1mnz97m/transcribe_youtube_video_failed_failed_to_extract/
- How to Scrape YouTube in 2026: Videos, Channels, Comments, and Metadata, acessado em abril 1, 2026, https://dev.to/agenthustler/how-to-scrape-youtube-in-2026-videos-channels-comments-and-metadata-27pn
- youtube transcript scraping kept dying in production — here’s what 3 months of workarounds taught me : r/Python – Reddit, acessado em abril 1, 2026, https://www.reddit.com/r/Python/comments/1rmkl9k/youtube_transcript_scraping_kept_dying_in/
- jdepoix/youtube-transcript-api – GitHub, acessado em abril 1, 2026, https://github.com/jdepoix/youtube-transcript-api
- youtube-transcript-api/youtube_transcript_api/_api.py at master – GitHub, acessado em abril 1, 2026, https://github.com/jdepoix/youtube-transcript-api/blob/master/youtube_transcript_api/_api.py
- How to Scrape YouTube in 2026 – Scrapfly Blog, acessado em abril 1, 2026, https://scrapfly.io/blog/posts/how-to-scrape-youtube
- “YouTube is blocking requests from your IP.” – even with webshare · Issue #511 · jdepoix/youtube-transcript-api – GitHub, acessado em abril 1, 2026, https://github.com/jdepoix/youtube-transcript-api/issues/511
- Best YouTube transcript APIs compared (2026) | TranscriptAPI, acessado em abril 1, 2026, https://transcriptapi.com/blog/best-youtube-transcript-apis-compared
- YouTube’s transcript feature with proxy – DEV Community, acessado em abril 1, 2026, https://dev.to/thanhphuchuynh/youtubes-transcript-feature-with-proxy-5hm5
- Which proxy service works best for this api / youtube.com? · jdepoix youtube-transcript-api · Discussion #335 · GitHub, acessado em abril 1, 2026, https://github.com/jdepoix/youtube-transcript-api/discussions/335
- How to avoid IP bans when using youtube-transcript-api to fetch YouTube video transcripts? : r/LocalLLaMA – Reddit, acessado em abril 1, 2026, https://www.reddit.com/r/LocalLLaMA/comments/1mfij9a/how_to_avoid_ip_bans_when_using/
- youtube-transcript-api 0.4.4 – PyPI, acessado em abril 1, 2026, https://pypi.org/project/youtube-transcript-api/0.4.4/
- 6 Ways to Get YouTube Cookies for yt-dlp in 2026 — Only 1 Works – DEV Community, acessado em abril 1, 2026, https://dev.to/osovsky/6-ways-to-get-youtube-cookies-for-yt-dlp-in-2026-only-1-works-2cnb
- feat: Add browser cookie authentication for age-restricted videos#565 – GitHub, acessado em abril 1, 2026, https://github.com/jdepoix/youtube-transcript-api/pull/565
- youtube transcript : r/Integromat – Reddit, acessado em abril 1, 2026, https://www.reddit.com/r/Integromat/comments/1ei2n13/youtube_transcript/
- JuanBindez/pytubefix: Python3 library for downloading … – GitHub, acessado em abril 1, 2026, https://github.com/JuanBindez/pytubefix
- pytube oauth/po token bypass or automation – python – Stack Overflow, acessado em abril 1, 2026, https://stackoverflow.com/questions/78996809/pytube-oauth-po-token-bypass-or-automation
- Python: error while trying to scrape youtube – Stack Overflow, acessado em abril 1, 2026, https://stackoverflow.com/questions/53979893/python-error-while-trying-to-scrape-youtube
- Bypass bot-detection to get turkey (with Python) – YouTube, acessado em abril 1, 2026, https://www.youtube.com/watch?v=GyOCRHINtzU
- Stealthy Playwright Mode: Bypass CAPTCHAs and Bot-Detection! – YouTube, acessado em abril 1, 2026, https://www.youtube.com/watch?v=PnFD_gSmGUc
- How to fix: yt-dlp – ‘HTTP Error 403: Forbidden’ 2026 | Harmony, acessado em abril 1, 2026, https://www.youtube.com/watch?v=4YPaBPs27FM
- Keep getting a forbidden message on ytdlp : r/youtubedl – Reddit, acessado em abril 1, 2026, https://www.reddit.com/r/youtubedl/comments/1qplrr7/keep_getting_a_forbidden_message_on_ytdlp/
- yt-dlp release 2025.09.26 : r/youtubedl – Reddit, acessado em abril 1, 2026, https://www.reddit.com/r/youtubedl/comments/1nrfrzk/ytdlp_release_20250926/
- YouTube Transcript Scraper – Extract Video Subtitles – Apify, acessado em abril 1, 2026, https://apify.com/futurizerush/youtube-transcript-scraper
- API Documentation – Submit new caption order – Rev, acessado em abril 1, 2026, https://www.rev.com/api/orderspostcaption
- youtube-transcript | Skills Marketplace · LobeHub, acessado em abril 1, 2026, https://lobehub.com/pt-BR/skills/ngxtm-devkit-youtube-transcript
- How to Get YouTube Transcripts: A Complete Developer’s Guide | by Taimur Khan – Medium, acessado em abril 1, 2026, https://medium.com/@volods/how-to-get-youtube-transcripts-a-complete-developers-guide-b3f092eb0a96
- Youtube Transcript API in Python – Apify, acessado em abril 1, 2026, https://apify.com/canadesk/youtube-transcript/api/python
- Python Web Scraping Tutorial: Complete Guide 2026 – YouTube, acessado em abril 1, 2026, https://www.youtube.com/watch?v=YrVRx2c72ig
- YouTube video to Transcript API in Python – Apify, acessado em abril 1, 2026, https://apify.com/scrapingxpert/youtube-video-to-transcript/api/python
- Implementing Effective API Rate Limiting in Python | by PI | Neural Engineer – Medium, acessado em abril 1, 2026, https://medium.com/neural-engineer/implementing-effective-api-rate-limiting-in-python-6147fdd7d516
- Rate Limiting in Python – YouTube, acessado em abril 1, 2026, https://www.youtube.com/watch?v=ZlmhQ5Sd3XA
- Rate Limiting with Redis & Python – Complete Guide for Beginners – YouTube, acessado em abril 1, 2026, https://www.youtube.com/watch?v=lF9s6Sl-88M
- Rate Limiting for downloading transcripts/subtitles? : r/youtubedl – Reddit, acessado em abril 1, 2026, https://www.reddit.com/r/youtubedl/comments/1ltbol1/rate_limiting_for_downloading_transcriptssubtitles/
